Here s my (twenty-sixth) monthly but brief update about the activities I ve done in the F/L/OSS world.
Debian
This was my 35th month of actively contributing to Debian.
I became a DM in late March 2019 and a DD on Christmas 19! \o/
Just churning through the backlog again this month. Ugh.
Anyway, I did the following stuff in Debian:
Uploads and bug fixes:
rails (2:6.1.4.1+dfsg-3) - No-change rebuild for unstable.
Other $things:
Mentoring for newcomers.
Moderation of -project mailing list.
Ubuntu
This was my 10th month of actively contributing to Ubuntu.
Now that I ve joined Canonical to work on Ubuntu full-time, there s a bunch of things I do! \o/
I mostly worked on different things, I guess.
I was too lazy to maintain a list of things I worked on so there s
no concrete list atm. Maybe I ll get back to this section later or
will start to list stuff from next year onward, as I was doing before. :D
Debian (E)LTS
Debian Long Term Support (LTS) is a project to extend the lifetime of all Debian stable releases to (at least) 5 years. Debian LTS is not handled by the Debian security team, but by a separate group of volunteers and companies interested in making it a success.
And Debian Extended LTS (ELTS) is its sister project, extending support to the Jessie release (+2 years after LTS support).
This was my twenty-sixth month as a Debian LTS and seventeenth month as a Debian ELTS paid contributor.
I was assigned 30.00 hours for LTS and 45.00 hours for ELTS and worked on the following things:
Issued DLA 2836-1, fixing CVE-2021-43527, for nss.
For Debian 9 stretch, these problems have been fixed in version 2:3.26.2-1.1+deb9u3.
Started working on src:samba for CVE-2020-25717 to CVE-2020-25722 and CVE-2021-23192 for jessie and stretch, both.
The version difference b/w the suites are a bit too much for the patch(es) to be easily backported. I ve talked to Anton to work something out. \o/
Found the problem w/ libjdom1-java. Will have to roll the regression upload.
I ve prepared the patch but needs some testing to be finally rolled out. Same for jessie.
Issued ELA 524-1, fixing CVE-2021-43618, for gmp.
For Debian 8 jessie, these problems have been fixed in version 2:6.0.0+dfsg-6+deb8u1.
Issued ELA 525-1, fixing CVE-2021-43527, for nss.
For Debian 8 jessie, these problems have been fixed in version 2:3.26-1+debu8u14.
Started working on src:samba for CVE-2020-25717 to CVE-2020-25722 and CVE-2021-23192 for jessie and stretch, both.
The version difference b/w the suites are a bit too much for the patch(es) to be easily backported. I ve talked to Anton to work something out. \o/
Found the problem w/ libjdom1-java. Will have to roll the regression upload.
I ve prepared the patch but needs some testing to be finally rolled out. Same for stretch.
Other (E)LTS Work:
Front-desk duty from 29-11 to 05-12 for both LTS and ELTS.
Dear lazy web...
I've had this code sitting around as a wtf.py for a while. I've been
meaning to understand what's going on and write a blog post about it
for a while, but I'm lacking the time. Now that I have a few minutes,
I actually sat down to look at it and I think I figured it out:
from contextlib import contextmanager
@contextmanagerdefbad():print(&aposin the context manager&apos)try:print("yielding value")yield&aposvalue&aposfinally:return print(&aposcleaning up&apos)@contextmanagerdefgood():print(&aposin the context manager&apos)try:print("yielding value")yield&aposvalue&aposfinally:print(&aposcleaning up&apos)
with bad()as v:print(&aposgot v =%s&apos% v)raiseException(&aposexception not raised!&apos)# SILENCED!print("this code is reached")
with good()as v:print(&aposgot v =%s&apos% v)raiseException(&aposexpection normally raised&apos)print("NOT REACHED (expected)")
For those, like me, who need a walkthrough, here's what the above
does:
define a good context manager in much the same way, except it
doesn't return, it just prints statement
use the bad context manager to show how it bypasses an exception
use the good context manager to show how it correctly raises the
exception
The output of this code (in Debian 11 bullseye, Python 3.9.2) is:
in the context manager
yielding value
got v = value
cleaning up
this code is reached
in the context manager
yielding value
got v = value
cleaning up
Traceback (most recent call last):
File "/home/anarcat/wikis/anarc.at/wtf.py", line 31, in <module>
raise Exception('expection normally raised')
Exception: expection normally raised
What is surprising to me, with this code, is not only does the
exception not get raised, but also the return statement doesn't seem
to actually execute, or at least not in the parent scope: if it would,
this code is reached wouldn't be printed and the rest of the code
wouldn't run either.
So what's going on here? Now I know that I should be careful with
return in my context manager, but why? And why is it silencing the
exception?
The reason why it's being silenced is this little chunk in the with
documentation:
If the suite was exited due to an exception, and the return value
from the exit() method was false, the exception is reraised. If
the return value was true, the exception is suppressed, and
execution continues with the statement following the with
statement.
This feels a little too magic. If you write a context manager with
__exit__(), you're kind of forced to lookup again what that API
is. But the contextmanager decorator hides that away and it's easy
to make that mistake...
Credits to the Python tips book for teaching me about that trick
in the first place.
The Motoko programming language has a built-in data type for optional values, named ?t with values null and ?v (for v : t); this is the equivalent of Haskell s Maybe, Ocaml s option or Rust s Option. In this post, I explain how Motoko represents such optional values (almost) without allocation.
I neither claim nor expect that any of this is novel; I just hope it s interesting.
Uniform representation
The Motoko programming language, designed by Andreas Rossberg and implemented by a pretty cool team at DFINITY is a high-level language with strict semantics and a strong, structural, equi-recursive type system that compiles down to WebAssembly.
Because the type system supports polymorphism, it represents all values uniformly. Simplified for the purpose of this blog post, they are always pointers into a heap object where the first word of the heap object, the heap tag, contains information about the value:
tag
The tag is something like array, int64, blob, variant, record, , and it has two purposes:
The garbage collector uses it to understand what kind of object it is looking at, so that it can move it around and follow pointers therein. Variable size objects such as arrays include the object size in a subsequent word of the heap object.
Some types have values that may have different shapes on the heap. For example, the ropes used in our text representation can either be a plain blob, or a concatenation node of two blobs. For these types, the tag of the heap object is inspected.
The optional type, naively
The optional type (?t) is another example of such a type: Its values can either be null, or ?v for some value v of type t, and the primitive operations on this type are the two introduction forms, an analysis function, and a projection for non-null values:
null : () -> ?t
some : t -> ?t
is_some : ?t -> bool
project : ?t -> t // must only be used if is_some holds
It is natural to use the heap tag to distinguish the two kind of values:
The null value is a simple one-word heap object with just a tag that says that this is null:
null
The other values are represented by a two-word object: The tag some, indicating that it is a ?v, and then the payload, which is the pointer that represents the value v:
some payload
With this, the four operations can be implemented as follows:
The problem with this implementation is that null() and some(v) both allocate memory. This is bad if they are used very often, and very liberally, and this is the case in Motoko: For example the iterators used for the for (x in e) construct have type
type Iter<T> = next : () -> ?T
and would unavoidably allocate a few words on each iteration. Can we avoid this?
Static values
It is quite simple to avoid this for for null: Just statically create a single null value and use it every time:
This way, at least null() doesn t allocate. But we gain more: Now everynull value is represented by the same pointer, and since the pointer points to static memory, it does not change even with a moving garbage collector, so we can speed up is_some:
def is_some(p):
return p != static_null
This is not a very surprising change so far, and most compilers out there can and will do at least the static allocation of such singleton constructors.
For example, in Haskell, there is only a single empty list ([]) and a single Nothing value in your program, as you can see in my videos exploring the Haskell heap.
But can we get rid of the allocation in some(v) too?
Unwrapped optional values
If we don t want to allocate in some(v), what can we do? How about simply
def some(v):
return v
That does not allocate! But it is also broken. At type ??Int, the values null, ?null and ??null are distinct values, but here this breaks.
Or, more formally, the following laws should hold for our four primitive operations:
is_some(null()) = false
v. is_some(some(v)) = true
p. project(some(p)) = p
But with the new definition of some, we d get is_some(some(null())) = false. Not good!
But note that we only have a problem if we are wrapping a value that is null or some(v). So maybe take the shortcut only then, and write the following:
def some(v):
if v == static_null v[0] == SOME_TAG:
ptr <- alloc(2)
ptr[0] = SOME_TAG
ptr[1] = v
return ptr
else:
return v
The definition of is_some can stay as it is: It is still the case that all null values are represented by static_null. But the some values are now no longer all of the same shape, so we have to change project():
def project(p):
if p[0] == SOME_TAG:
return p[1]
else:
return p
Now things fall into place: A value ?v can, in many cases, be represented the same way as v, and no allocation is needed. Only when v is null or ?null or ??null or ???null etc. we need to use the some heap object, and thus have to allocate.
In fact, it doesn t cost much to avoid allocation even for ?null:
static_some_null = [SOME_TAG, static_null]
def some(v):
if v == static_null:
return static_some_null
else if v[0] == SOME_TAG:
ptr <- alloc(2)
ptr[0] = SOME_TAG
ptr[1] = v
return ptr
else:
return v
So unless one nests the ? type two levels deep, there is no allocation whatsoever, and the only cost is a bit more branching in some and project.
That wasn t hard, but quite rewarding, as one can now use idioms like the iterator shown above with greater ease.
Examples
The following tables shows the representation of various values before and after. Here [ ] is a pointed-to dynamically allocated heap object, a statically allocated heap object, N = NULL_TAG and S = SOME_TAG.
type
value
before
after
Null
null
N
N
?Int
null
N
N
?Int
?23
[S,23]
23
??Int
null
N
N
??Int
?null
[S, N ]
S, N
??Int
??23
[S,[S,23]]
23
???Int
null
N
N
???Int
?null
[S, N ]
S, N
???Int
??null
[S,[S, N ]]
[S, S, N ]
???Int
???23
[S,[S,[S,23]]]
23
Concluding remarks
If you know what parametric polymorphism is, and wonder how this encoding can work in a language that has that, note that this representation is on the low-level of the untyped run-time value representation: We don t need to know the type of v in some(v), merely its heap representation.
The uniform representation in Motoko is a bit more involved: The pointers are tagged (by subtracting 1) and some scalar values are represented directly in place (shifted left by 1 bit). But this is luckily orthogonal to what I showed here.
Could Haskell do this for its Maybe type? Not so easily:
The Maybe type is not built-in, but rather a standard library-defined algebraic data type. But the compiler could feasible detect that this is option-like?
Haskell is lazy, so at runtime, the type Maybe could be Nothing, or Just v, or, and this is crucial, a yet to be evaluated expression, also called a thunk. And one definitely needs to distinguish between a thunk t :: Maybe a that may evaluate to Nothing, and a value Just t :: Maybe a that definitely isJust, but contains a value, which may be a thunk.
As I said above, I don t expect this to be novel, and I am happy to add references to prior art here.
Given that a heap object with tag SOME_TAG now always encodes a tower ? null for n>0, one could try to optimize that even more by just storing the n:
some n
But that seems unadvisable: It is only a win if you have deep towers, which is probably rare. Worse, now the project function would have to return such a heap object with n decremented, so now projection might have to allocate, which goes against the cost model expected by the programmer.
If you rather want to see code than blog posts, feel free to check out Motoko PR #2115.
Does this kind of stuff excite you? Motoko is open source, so your contributions may be welcome!
The goal behind reproducible builds is to ensure that no deliberate flaws have been introduced during compilation processes via promising or mandating that identical results are always generated from a given source. This allowing multiple third-parties to come to an agreement on whether a build was compromised or not by a system of distributed consensus.
In these reports we outline the most important things that have been happening in the world of reproducible builds in the past month:
First mentioned in our March 2021 report, Martin Heinz published two blog posts on sigstore, a project that endeavours to offer software signing as a public good, [the] software-signing equivalent to Let s Encrypt . The two posts, the first entitled Sigstore: A Solution to Software Supply Chain Security outlines more about the project and justifies its existence:
Software signing is not a new problem, so there must be some solution already, right? Yes, but signing software and maintaining keys is very difficult especially for non-security folks and UX of existing tools such as PGP leave much to be desired. That s why we need something like sigstore - an easy to use software/toolset for signing software artifacts.
Some time ago I checked Signal s reproducibility and it failed. I asked others to test in case I did something wrong, but nobody made any reports. Since then I tried to test the Google Play Store version of the apk against one I compiled myself, and that doesn t match either.
BitcoinBinary.org was announced this month, which aims to be a repository of Reproducible Build Proofs for Bitcoin Projects :
Most users are not capable of building from source code themselves, but we can at least get them able enough to check signatures and shasums. When reputable people who can tell everyone they were able to reproduce the project s build, others at least have a secondary source of validation.
Related to this, there was continuing discussion on how to embed/encode the build metadata for the Debian live images which were being worked on by Roland Clobus.
Ariadne Conill published another detailed blog post related to various security initiatives within the Alpine Linux distribution. After summarising some conventional security work being done (eg. with sudo and the release of OpenSSH version 3.0), Ariadne included another section on reproducible builds: The main blocker [was] determining what to do about storing the build metadata so that a build environment can be recreated precisely .
Finally, Bernhard M. Wiedemann posted his monthly reproducible builds status report.
Community news
On our website this month, Bernhard M. Wiedemann fixed some broken links [] and Holger Levsen made a number of changes to the Who is Involved? page [][][]. On our mailing list, Magnus Ihse Bursie started a thread with the subject Reproducible builds on Java, which begins as follows:
I m working for Oracle in the Build Group for OpenJDK which is primary responsible for creating a built artifact of the OpenJDK source code. [ ] For the last few years, we have worked on a low-effort, background-style project to make the build of OpenJDK itself building reproducible. We ve come far, but there are still issues I d like to address. []
diffoscopediffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb prepared and uploaded versions 183, 184 and 185 as well as performed significant triaging of merge requests and other issues in addition to making the following changes:
New features:
Support a newer format version of the R language s .rds files. []
Don t call close_archive when garbage collecting Archive instances, unless open_archive definitely returned successfully. This prevents, for example, an AttributeError where PGPContainer s cleanup routines were rightfully assuming that its temporary directory had actually been created. []
Fix (and test) the comparison of R language s .rdb files after refactoring temporary directory handling. []
Ensure that RPM archives exists in the Debian package description, regardless of whether python3-rpm is installed or not at build time. []
Codebase improvements:
Use our assert_diff routine in tests/comparators/test_rdata.py. []
Move diffoscope.versions to diffoscope.tests.utils.versions. []
Reformat a number of modules with Black. [][]
However, the following changes were also made:
Mattia Rizzolo:
Fix an autopkgtest caused by the androguard module not being in the (expected) python3-androguard Debian package. []
Appease a shellcheck warning in debian/tests/control.sh. []
Ignore a warning from h5py in our tests that doesn t concern us. []
Drop a trailing .1 from the Standards-Version field as it s required. []
Zbigniew J drzejewski-Szmek:
Stop using the deprecated distutils.spawn.find_executable utility. [][][][][]
Adjust an LLVM-related test for LLVM version 13. []
Update invocations of llvm-objdump. []
Adjust a test with a one-byte text file for file version 5.40. []
And, finally, Benjamin Peterson added a --diff-context option to control unified diff context size [] and Jean-Romain Garnier fixed the Macho comparator for architectures other than x86-64 [].
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
#990246 filed against vlc (forwarded upstream [][])
Testing framework
The Reproducible Builds project runs a testing framework at tests.reproducible-builds.org, to check packages and other artifacts for reproducibility. This month, the following changes were made:
Holger Levsen:
Drop my package rebuilder prototype as it s not useful anymore. []
Schedule old packages in Debian bookworm. []
Stop scheduling packages for Debian buster. [][]
Don t include PostgreSQL debug output in package lists. []
Detect Python library mismatches during build in the node health check. []
Update a note on updating the FreeBSD system. []
Mattia Rizzolo:
Silence a warning from Git. []
Update a setting to reflect that Debian bookworm is the new testing. []
Upgrade the PostgreSQL database to version 13. []
Roland Clobus (Debian live image generation):
Workaround non-reproducible config files in the libxml-sax-perl package. []
Use the new DNS for the snapshot service. []
Vagrant Cascadian:
Also note that the armhf architecture also systematically varies by the kernel. []
Contributing
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
I have been using the awesome window manager for 10 years. It is a
tiling window manager, configurable and extendable with the
Lua language. Using a general-purpose programming language to
configure every aspect is a double-edged sword. Due to laziness and
the apparent difficulty of adapting my configuration about 3000 lines to newer releases, I was stuck with the 3.4
version, whose last release is from 2013.
It was time for a rewrite. Instead, I have switched to the i3 window
manager, lured by the possibility to migrate to Wayland and
Sway later with minimal pain. Using an embedded interpreter for
configuration is not as important to me as it was in the past: it
brings both complexity and brittleness.
Dual screen desktop running i3, Emacs, some terminals, including a Quake console, Firefox, Polybar as the status bar, and Dunst as the notification daemon.
The window manager is only one part of a desktop environment. There
are several options for the other components. I am also introducing
them in this post.
i3: the window manageri3 aims to be a minimal tiling window manager. Its documentation
can be read from top to bottom in less than an hour. i3 organize
windows in a tree. Each non-leaf node contains one or several
windows and has an orientation and a layout. This information
arbitrates the window positions. i3 features three layouts: split,
stacking, and tabbed. They are demonstrated in the below screenshot:
Demonstration of the layouts available in i3. The main container is split horizontally. The first child is split vertically. The second one is tabbed. The last one is stacking.
Tree representation of the previous screenshot.
Most of the other tiling window managers, including the awesome
window manager, use predefined layouts. They usually feature a large
area for the main window and another area divided among the remaining
windows. These layouts can be tuned a bit, but you mostly stick to a
couple of them. When a new window is added, the behavior is quite
predictable. Moreover, you can cycle through the various windows
without thinking too much as they are ordered.
i3 is more flexible with its ability to build any layout on the fly,
it can feel quite overwhelming as you need to visualize the tree in
your head. At first, it is not unusual to find yourself with a complex
tree with many useless nested containers. Moreover, you have to
navigate windows using directions. It takes some time to get used to.
I set up a split layout for Emacs and a few terminals, but most of the
other workspaces are using a tabbed layout. I don t use the stacking
layout. You can find many scripts trying to emulate other tiling
window managers but I did try to get my setup pristine of these
tentatives and get a chance to familiarize myself. i3 can also save
and restore layouts, which is quite a powerful feature.
My configuration is quite similar to the default one and has
less than 200 lines.
i3 companion: the missing bitsi3 philosophy is to keep a minimal core and let the user implements
missing features using the IPC protocol:
Do not add further complexity when it can be avoided. We are
generally happy with the feature set of i3 and instead focus on
fixing bugs and maintaining it for stability. New features will
therefore only be considered if the benefit outweighs the additional
complexity, and we encourage users to implement features using the
IPC whenever possible.
Introduction to the i3 window manager
While this is not as powerful as an embedded language, it is enough
for many cases. Moreover, as high-level features may be opinionated,
delegating them to small, loosely coupled pieces of code keeps them
more maintainable. Libraries exist for this purpose in several
languages. Users have published many scripts to extend i3:
automatic layout and window promotion to mimic the behavior
of other tiling window managers, window swallowing to put a new
app on top of the terminal launching it, and cycling between
windows with Alt+Tab.
Instead of maintaining a script for each feature, I have centralized
everything into a single Python process,
i3-companion using asyncio and the
i3ipc-python library. Each feature is self-contained into a
function. It implements the following components:
make a workspace exclusive to an application
When a workspace contains Emacs or Firefox, I would like other
applications to move to another workspace, except for the terminal
which is allowed to intrude into any workspace. The
workspace_exclusive() function monitors new windows and moves them
if needed to an empty workspace or to one with the same application
already running.
implement a Quake console
The quake_console() function implements a drop-down console
available from any workspace. It can be toggled with
Mod+. This is implemented as a scratchpad
window.
back and forth workspace switching on the same output
With the workspace back_and_forth command, we can ask i3 to
switch to the previous workspace. However, this feature is not
restricted to the current output. I prefer to have one keybinding to
switch to the workspace on the next output and one keybinding to
switch to the previous workspace on the same output. This behavior
is implemented in the previous_workspace() function by keeping a
per-output history of the focused workspaces.
create a new empty workspace or move a window to an empty workspace
To create a new empty workspace or move a window to an empty
workspace, you have to locate a free slot and use workspace number
4 or move container to workspace number 4. The new_workspace()
function finds a free number and use it as the target workspace.
restart some services on output change
When adding or removing an output, some actions need to be executed:
refresh the wallpaper, restart some components unable to adapt their
configuration on their own, etc. i3 triggers an event for this
purpose. The output_update() function also takes an extra step to
coalesce multiple consecutive events and to check if there is a real
change with the low-level library xcffib.
I will detail the other features as this post goes on. On the
technical side, each function is decorated with the events it should
react to:
@on(CommandEvent("previous-workspace"),I3Event.WORKSPACE_FOCUS)asyncdefprevious_workspace(i3,event):"""Go to previous workspace on the same output."""
The CommandEvent() event class is my way to send a command to the
companion, using either i3-msg -t send_tick or binding a key to a
nop command. The latter is used to avoid spawning a shell and a
i3-msg process just to send a message. The companion listens to
binding events and checks if this is a nop command.
bindsym $mod+Tab nop "previous-workspace"
There are other decorators to avoid code duplication: @debounce() to
coalesce multiple consecutive calls, @static() to define a static
variable, and @retry() to retry a function on failure. The whole
script is a bit more than 1000 lines. I think this is
worth a read as I am quite happy with the result.
dunst: the notification daemon
Unlike the awesome window manager, i3 does not come with a built-in
notification system. Dunst is a lightweight notification daemon. I
am running a modified version with HiDPI support for X11 and
recursive icon lookup. The i3 companion has a helper function,
notify(), to send notifications using DBus. container_info() and
workspace_info() uses it to display information about the container
or the tree for a workspace.
Notification showing i3 s tree for a workspace
polybar: the status bari3 bundles i3bar, a versatile status bar, but I have opted for
Polybar. A wrapper script runs one instance for
each monitor.
The first module is the built-in support for i3 workspaces. To not
have to remember which application is running in a workspace, the i3
companion renames workspaces to include an icon for each application.
This is done in the workspace_rename() function. The icons are from
the Font Awesome project. I maintain a mapping between applications
and icons. This is a bit cumbersome but it looks great.
i3 workspaces in Polybar
For CPU, memory, brightness, battery, disk, and audio volume, I am
relying on the built-in modules. Polybar s wrapper script generates the list of filesystems to monitor and they get only
displayed when available space is low. The battery widget turns red
and blinks slowly when running out of power. Check my Polybar
configuration for more details.
Polybar displaying various information: CPU usage, memory usage, screen brightness, battery status, Bluetooth status (with a connected headset), network status (connected to a wireless network and to a VPN), notification status, and speaker volume.
For Bluetooh, network, and notification statuses, I am using Polybar s
ipc module: the next version of Polybar can receive
an arbitrary text on an IPC socket. The module is defined with a
single hook to be executed at the start to restore the latest status.
It can be updated with polybar-msg action "#network.send.XXXX". In
the i3 companion, the @polybar() decorator takes the string
returned by a function and pushes the update through the IPC socket.
The i3 companion reacts to DBus signals to update the Bluetooth and
network icons. The @on() decorator accepts a DBusSignal() object:
@on(StartEvent,DBusSignal(path="/org/bluez",interface="org.freedesktop.DBus.Properties",member="PropertiesChanged",signature="sa sv as",onlyif=lambdaargs:(args[0]=="org.bluez.Device1"and"Connected"inargs[1]orargs[0]=="org.bluez.Adapter1"and"Powered"inargs[1]),),)@retry(2)@debounce(0.2)@polybar("bluetooth")asyncdefbluetooth_status(i3,event,*args):"""Update bluetooth status for Polybar."""
The middle of the bar is occupied by the date and a weather forecast.
The latest also uses the IPC mechanism, but the source is a Python
script triggered by a timer.
Current date and weather forecast for the day in Polybar. The data is retrieved with the OpenWeather API.
I don t use the system tray integrated with Polybar. The embedded
icons usually look horrible and they all behave differently. A few
years back, Gnome has removed the system tray. Most of the
problems are fixed by the DBus-based Status Notifier Item
protocol also known as Application Indicators or Ayatana
Indicators for GNOME. However, Polybar does not support this
protocol. In the i3 companion, The implementation of Bluetooth
and network icons, including displaying notifications on change, takes
about 200 lines. I got to learn a bit about how DBus works and I get exactly
the info I want.
picom: the compositor
I like having slightly transparent backgrounds for terminals and to
reduce the opacity of unfocused windows. This requires a
compositor.1picom is a lightweight compositor. It works
well for me, but it may need some tweaking depending on your graphic
card.2 Unlike the awesome window manager, i3 does not handle
transparency, so the compositor needs to decide by itself the opacity
of each window. Check my configuration for details.
systemd: the service manager
I use systemd to start i3 and the various services around it. My
xsession script only sets some environment variables and lets
systemd handles everything else. Have a look at this article from
Micha G ral for the rationale. Notably, each component can be
easily restarted and their logs are not mangled inside the
~/.xsession-errors file.3
I am using a two-stage setup: i3.service depends on
xsession.target to start services before
i3:
rofi: the application launcherRofi is an application launcher. Its appearance can be customized
through a CSS-like language and it comes with several themes. Have a
look at my configuration for mine.
Rofi as an application launcher
It can also act as a generic menu application. I have a script
to control a media player and another one to
select the wifi network. It is quite a flexible
application.
Rofi to select a wireless network
xss-lock and i3lock: the screen lockeri3lock is a simple screen locker. xss-lock invokes it reliably
on inactivity or before a system suspend. For inactivity, it uses the
XScreenSaver events. The delay is configured using the xset s
command. The locker can be invoked immediately with xset s activate.
X11 applications know how to prevent the screen saver from running. I
have also developed a small dimmer application that is executed 20
seconds before the locker to give me a chance to move the mouse if I
am not away.4 Have a look at my configuration
script.
Demonstration of xss-lock, xss-dimmer and i3lock with a 4 speedup.
The remaining components
autorandr is a tool to detect the connected display, match them
against a set of profiles, and configure them with xrandr.
inputplug executes a script for each new mouse and keyboard
plugged. This is quite useful to load the appropriate the keyboard
map. See my configuration.
xsettingsd provides settings to X11 applications, not unlike
xrdb but it notifies applications for changes. The main use is
to configure the Gtk and DPI settings. See my article on HiDPI
support on Linux with X11.
Redshift adjusts the color temperature of the screen according
to the time of day.
maim is a utility to take screenshots. I use Prt Scn
to trigger a screenshot of a window or a specific area and
Mod+Prt Scn to capture the whole desktop to a
file. Check the helper script for details.
I have a collection of wallpapers I rotate every hour. A
script selects them using advanced machine learning
algorithms and stitches them together on multi-screen setups. The
selected wallpaper is reused by i3lock.
Apart from the eye candy, a compositor also helps to get
tear-free video playbacks.
My configuration works with both Haswell (2014) and Whiskey
Lake (2018) Intel GPUs. It also works with AMD GPU based on the
Polaris chipset (2017).
You cannot manage two different displays this way e.g.
:0 and :1. In the first implementation, I did try to
parametrize each service with the associated display, but this is
useless: there is only one DBus user session and many services
rely on it. For example, you cannot run two notification daemons.
I have only discovered later that XSecureLock ships
such a dimmer with a similar implementation. But mine has a cool
countdown!
Here s my (twenty-third) monthly but brief update about the activities I ve done in the F/L/OSS world.
Debian
This was my 32nd month of actively contributing to Debian.
I became a DM in late March 2019 and a DD on Christmas 19! \o/
Tough month but I mostly spent on it churning through the immense backlog. But that
somewhat backfired and I have even more backlog than ever. :D
Anyway, I did the following stuff in Debian:
Ubuntu
This was my 7th month of actively contributing to Ubuntu.
Now that I ve joined Canonical to work on Ubuntu full-time, there s a bunch of things I do! \o/
I mostly worked on different things, I guess. But mostly on packaging keylime and some Google Agents upload(s) and SRU(s). Also did a lot of reviewing, et al.
I was too lazy to maintain a list of things I worked on so there s no concrete list atm. Maybe I ll get back to this section later or will start to list stuff from next month onward, as I ve been doing before. :D
Debian (E)LTS
Debian Long Term Support (LTS) is a project to extend the lifetime of all Debian stable releases to (at least) 5 years. Debian LTS is not handled by the Debian security team, but by a separate group of volunteers and companies interested in making it a success.
And Debian Extended LTS (ELTS) is its sister project, extending support to the Jessie release (+2 years after LTS support).
This was my twenty-third month as a Debian LTS and eleventh month as a Debian ELTS paid contributor.
I was assigned 23.75 hours for LTS and 40.00 hours for ELTS and worked on the following things:
(however, I only worked for 23.75h on ELTS work, thereby, carrying the rest to next month)
Noticed that there s a fallout of CVE-2021-3185, where an update was issued for gst-plugins-bad1.0, however, not for gst-plugins-bad0.10.
Thanks to Sylvain s script, this came up and I prepped an update for that.
Started to work on libjdom1-java s regression.
Other (E)LTS Work:
Front-desk duty from 26-07 until 01-08 and from 30-08 until 05-09 for both LTS and ELTS.
Mark CVE-2021-39240/haproxy as not-affected for stretch and jessie.
Mark CVE-2021-39241/haproxy as not-affected for stretch and jessie.
Mark CVE-2021-39242/haproxy as not-affected for stretch and jessie.
Mark CVE-2021-33582/cyrus-imapd as no-dsa for stretch.
Mark CVE-2020-18771/exiv2 as no-dsa for exiv2 for stretch.
Mark CVE-2020-18899/exiv2 as no-dsa for exiv2 for stretch.
Mark CVE-2021-38171/ffmpeg as postponed for stretch.
Mark CVE-2021-40330/git as no-dsa for stretch and jessie.
Mark CVE-2020-19481/gpac as ignored for stretch.
Mark CVE-2021-40491/inetutils as no-dsa for stretch.
Mark CVE-2021-36370/mc as no-dsa for stretch and jessie.
Mark CVE-2021-35368/modsecurity-crs as no-dsa for stretch.
Mark CVE-2021-23434/node-object-path as end-of-life for stretch.
Mark CVE-2021-32610/php-pear as no-dsa for stretch.
Mark CVE-2017-9525/systemd-cron as no-dsa for stretch.
Mark CVE-2021-37701/node-tar as end-of-life for stretch.
Mark CVE-2021-37712/node-tar as end-of-life in stretch.
Mark CVE-2021-3750/qemu as postponsed for jessie.
Mark CVE-2021-27511/prototypejs as postponsed for jessie.
Mark CVE-2021-23437/pillow as postponed for stretch and jessie.
Auto EOL ed gpac, cacti, openscad, cgal, cyrus-imapd-2.4, libsolv, mosquitto, atomicparsley, gtkpod, node-tar, libapache2-mod-auth-openidc, neutron, inetutils and linux for jessie.
Drop cpio from ela-needed; open issues don t warrant an ELA.
Attended monthly Debian LTS meeting.
Answered questions (& discussions) on IRC (#debian-lts and #debian-elts).
I have a cheap no-name UPS acquired from Jaycar and was wondering if I
could get it to connect to my Synology DS918+. It rather unhelpfully
identifies itself as MEC0003 and comes with some blob of
non-working software on a CD; however some investigation found it
could maybe work on my Synology NAS using the Network UPS Toolsnutdrv_qx driver with the
hunnox subdriver type.
Unfortunately this is a fairly recent addition to the NUTs source,
requiring rebuilding the driver for DSM7. I don't fully understand
the Synology environment but I did get this working. Firstly I
downloaded the toolchain from
https://archive.synology.com/download/ToolChain/toolchain/ and
extracted it. I then used the script from
https://github.com/SynologyOpenSource/pkgscripts-ng to download
some sort of build environment. This appears to want root access and
possibly sets up some sort of chroot. Anyway, for DSM7 on the DS918+
I ran EnvDeploy -v 7.0 -p apollolake and it downloaded some
tarballs into toolkit_tarballs that I simply extracted into the
same directory as the toolchain.
I then grabbed the NUTs source from
https://github.com/networkupstools/nut. I then built NUTS
similar to the following
The tricks to be aware of are setting the locations DSM wants
status/config files and overriding the USB detection done by
configure which doesn't seem to obey sysroot.
If you would prefer to avoid this you can try this prebuilt nutdrv_qx
(ebb184505abd1ca1750e13bb9c5f991eaa999cbea95da94b20f66ae4bd02db41).
SSH to the DSM7 machine; as root move /usr/bin/nutdrv_qx out of
the way to save it; scp the new version and move it into place.
If you cat /dev/bus/usb/devices I found this device has a Vendor
0001 and ProdID 0000.
DSM does a bunch of magic to autodetect and configure NUTs when a UPS
is plugged in. The first thing you'll need to do is edit
/etc/nutscan-usb.sh and override where it tries to use the
blazer_usb driver for this obviously incorrect vendor/product id.
The line should now look like
Then you want to edit the file
/usr/syno/lib/systemd/scripts/ups-usb.sh to start the
nutdrv_qx; find the DRV_LIST in that file and update it like
so:
local DRV_LIST="nutdrv_qx usbhid-ups blazer_usb bcmxcp_usb richcomm_usb tripplite_usb"
This is triggered by /usr/lib/systemd/system/ups-usb.service and
is ultimately what tries to setup the UPS configuration.
Lastly, you will need to edit the /etc/ups/ups.conf file. This
will probably vary depending on your UPS. One important thing is to
add user=root above the driver; it seems recent NUT has become
more secure and drops permissions, but the result it will not find USB
devices in this environment (if you're getting something like no
appropriate HID device found this is likely the cause). So the
configuration should look something like:
I then restarted the UPS daemon by enabling/disabling UPS support in
the UI. This should tell you that your UPS is connected. You can
also check /var/log/ups.log which shows for me
Which corresponds to the correct input/output voltage and state.
Of course this is all unsupported and probably likely to break --
although I don't imagine much of these bits are updated very
frequently. It will likely be OK until the UPS battery dies; at which
point I would reccommend buying a better UPS on the Synology support
list.
After a very long porting journey,
Launchpad is finally running on Python 3 across
all of our systems.
I wanted to take a bit of time to reflect on why my emotional responses to
this port differ so much from those of some others who ve done large ports,
such as the Mercurial
maintainers.
It s hard to deny that we ve had to burn a lot of time on this, which I m
sure has had an opportunity cost, and from one point of view it s
essentially running to stand still: there is no single compelling feature
that we get solely by porting to Python 3, although it s clearly a
prerequisite for tidying up old compatibility code and being able to use
modern language facilities in the future. And yet, on the whole, I found
this a rewarding project and enjoyed doing it.
Some of this may be because by inclination I m a maintenance programmer and
actually enjoy this sort of thing. My default view tends to be that
software version upgrades may be a pain but it s much better to get that
pain over with as soon as you can rather than trying to hold back the tide;
you can certainly get involved and try to shape where things end up, but
rightly or wrongly I can t think of many cases when a righteously indignant
user base managed to arrange for the old version to be maintained in
perpetuity so that they never had to deal with the new thing (OK, maybe Perl
5 counts here).
I think a more compelling difference between Launchpad and Mercurial,
though, may be that very few other people really had a vested interest in
what Python version Launchpad happened to be running, because it s all
server-side code (aside from some client libraries such as
launchpadlib, which were ported
years ago). As such, we weren t trying to do this with the internet having
Strong Opinions at us. We were doing this because it was obviously the only
long-term-maintainable path forward, and in more recent times because some
of our library dependencies were starting to drop support for Python 2 and
so it was obviously going to become a practical problem for us sooner or
later; but if we d just stayed on Python 2 forever then fundamentally hardly
anyone else would really have cared directly, only maybe about some indirect
consequences of that. I don t follow Mercurial development so I may be
entirely off-base, but if other people were yelling at me about how late my
project was to finish its port, that in itself would make me feel more
negatively about the project even if I thought it was a good idea. Having
most of the pressure come from ourselves rather than from outside meant that
wasn t an issue for us.
I m somewhat inclined to think of the process as an extreme version of
paying down technical debt. Moving from Python 2.7 to 3.5, as we just did,
means skipping over multiple language versions in one go, and if similar
changes had been made more gradually it would probably have felt a lot more
like the typical dependency update treadmill. I appreciate why not everyone
might want to think of it this way: maybe this is just my own rationalization.
Reflections on porting to Python 3
I m not going to defend the Python 3 migration process; it was pretty rough
in a lot of ways. Nor am I going to spend much effort relitigating it here,
as it s already been done to death elsewhere, and as I understand it the
core Python developers have got the message loud and clear by now. At a
bare minimum, a lot of valuable time was lost early in Python 3 s lifetime
hanging on to flag-day-type porting strategies that were impractical for
large projects, when it should have been providing for bilingual
strategies (code that runs in both Python 2 and 3 for a transitional period)
which is where most libraries and most large migrations ended up in
practice. For instance, the early advice to library maintainers to maintain
two parallel versions or perhaps translate dynamically with 2to3 was
entirely impractical in most non-trivial cases and wasn t what most people
ended up doing, and yet the idea that 2to3 is all you need still floats
around Stack Overflow and the like as a result. (These days, I would
probably point people towards something more like Eevee s porting
FAQ
as somewhere to start.)
There are various fairly straightforward things that people often suggest
could have been done to smooth the path, and I largely agree: not removing
the u'' string prefix only to put it back in 3.3, fewer gratuitous
compatibility breaks in the name of tidiness, and so on. But if I had a
time machine, the number one thing I would ask to have been done differently
would be introducing type annotations in Python 2 before Python 3 branched
off. It s true that it s technically
possible
to do type annotations in Python 2, but the fact that it s a different
syntax that would have to be fixed later is offputting, and in practice it
wasn t widely used in Python 2 code. To make a significant difference to
the ease of porting, annotations would need to have been introduced early
enough that lots of Python 2 library code used them so that porting code
didn t have to be quite so much of an exercise of manually figuring out the
exact nature of string types from context.
Launchpad is a complex piece of software that interacts with multiple
domains: for example, it deals with a database, HTTP, web page rendering,
Debian-format archive publishing, and multiple revision control systems, and
there s often overlap between domains. Each of these tends to imply
different kinds of string handling. Web page rendering is normally done
mainly in Unicode, converting to bytes as late as possible; revision control
systems normally want to spend most of their time working with bytes,
although the exact details vary; HTTP is of course bytes on the wire, but
Python s WSGI interface has some string type
subtleties.
In practice I found myself thinking about at least four string-like types
(that is, things that in a language with a stricter type system I might well
want to define as distinct types and restrict conversion between them):
bytes, text, ordinary native strings (str in either language, encoded to
UTF-8 in Python 2), and native strings with WSGI s encoding rules. Some of
these are emergent properties of writing in the intersection of Python 2 and
3, which is effectively a specialized language of its own without coherent
official documentation whose users must intuit its behaviour by comparing
multiple sources of information, or by referring to unofficial porting
guides: not a very satisfactory situation. Fortunately much of the
complexity collapses once it becomes possible to write solely in Python 3.
Some of the difficulties we ran into are not ones that are typically thought
of as Python 2-to-3 porting issues, because they were changed later in
Python 3 s development process. For instance, the email module was
substantially improved in around the 3.2/3.3 timeframe to handle Python 3 s
bytes/text model more correctly, and since Launchpad sends quite a few
different kinds of email messages and has some quite picky tests for exactly
what it emits, this entailed a lot of work in our email sending code and in
our test suite to account for that. (It took me a while to work out whether
we should be treating raw email messages as bytes or as text; bytes turned
out to work best.) 3.4 made some tweaks to the implementation of
quoted-printable encoding that broke a number of our tests in ways that took
some effort to fix, because the tests needed to work on both 2.7 and 3.5.
The list goes on. I got quite proficient at digging through Python s git
history to figure out when and why some particular bit of behaviour had changed.
One of the thorniest problems was parsing HTTP form data. We mainly rely on
zope.publisher for this, which
in turn relied on
cgi.FieldStorage; but
cgi.FieldStorage is badly broken in some
situations on Python 3. Even if that
bug were fixed in a more recent version of Python, we can t easily use
anything newer than 3.5 for the first stage of our port due to the version
of the base OS we re currently running, so it wouldn t help much. In the
end I fixed some minor issues in the
multipart module (and was kindly
given co-maintenance of it) and converted zope.publisher to use
it. Although
this took a while to sort out, it seems to have gone very well.
A couple of other interesting late-arriving issues were around
pickle. For most things
we normally prefer safer formats such as JSON, but there are a few cases
where we use pickle, particularly for our session databases. One of my
colleagues pointed out that I needed to remember to tell pickle to stick
to protocol
2,
so that we d be able to switch back and forward between Python 2 and 3 for a
while; quite right, and we later ran into a similar problem with
marshal too. A more
surprising problem was that datetime.datetime objects pickled on Python 2
require special care when unpickling
on Python 3; rather than the approach that ended up being implemented and
documented
for Python 3.6, though, I preferred a custom
unpickler,
both so that things would work on Python 3.5 and so that I wouldn t have to
risk affecting the decoding of other pickled strings in the session database.
General lessons
Writing this over a year after Python 2 s end-of-life date, and certainly
nowhere near the leading edge of Python 3 porting work, it s perhaps more
useful to look at this in terms of the lessons it has for other large
technical debt projects.
I mentioned in my previous article that
I used the approach of an enormous and frequently-rebased git branch as a
working area for the port, committing often and sometimes combining and
extracting commits for review once they seemed to be ready. A port of this
scale would have been entirely intractable without a tool of similar power
to git rebase, so I m very glad that we finished migrating to git in 2019.
I relied on this right up to the end of the port, and it also allowed for
quick assessments of how much more there was to land. git
worktree was also helpful, in that I
could easily maintain working trees built for each of Python 2 and 3 for comparison.
As is usual for most multi-developer projects, all changes to Launchpad need
to go through code review, although we sometimes make exceptions for very
simple and obvious changes that can be self-reviewed. Since I knew from the
outset that this was going to generate a lot of changes for review, I
therefore structured my work from the outset to try to make it as easy as
possible for my colleagues to review it. This generally involved keeping
most changes to a somewhat manageable size of 800 lines or less (although
this wasn t always possible), and arranging commits mainly according to the
kind of change they made rather than their location. For example, when I
needed to fix issues with / in Python 3 being true division rather than
floor division, I did so in one
commit
across the various places where it mattered and took care not to mix it with
other unrelated changes. This is good practice for nearly any kind of
development, but it was especially important here since it allowed reviewers
to consider a clear explanation of what I was doing in the commit message
and then skim-read the rest of it much more quickly.
It was vital to keep the codebase in a working state at all times, and
deploy to production reasonably often: this way if something went wrong the
amount of code we had to debug to figure out what had happened was always
tractable. (Although I can t seem to find it now to link to it, I saw an
account a while back of a company that had taken a flag-day approach instead
with a large codebase. It seemed to work for them, but I m certain we
couldn t have made it work for Launchpad.)
I can t speak too highly of Launchpad s test suite, much of which originated
before my time. Without a great deal of extensive coverage of all sorts of
interesting edge cases at both the unit and functional level, and a
corresponding culture of maintaining that test suite well when making new
changes, it would have been impossible to be anything like as confident of
the port as we were.
As part of the porting work, we split out a couple of substantial chunks of
the Launchpad codebase that could easily be decoupled from the core: its
Mailman integration and its code import
worker. Both of these had substantial
dependencies with complex requirements for porting to Python 3, and
arranging to be able to do these separately on their own schedule was
absolutely worth it. Like disentangling balls of wool, any opportunity you
can take to make things less tightly-coupled is probably going to make it
easier to disentangle the rest. (I can see a tractable way forward to
porting the code import worker, so we may well get that done soon. Our
Mailman integration will need to be rewritten, though, since it currently
depends on the Python-2-only Mailman 2, and Mailman 3 has a different architecture.)
Python lessons
Our database layer was already in pretty good
shape for a port, since at least the modern bits of its table modelling
interface were already strict about using Unicode for text columns. If you
have any kind of pervasive low-level framework like this, then making it be
pedantic at you in advance of a Python 3 port will probably incur much less
swearing in the long run, as you won t be trying to deal with quite so many
bytes/text issues at the same time as everything else.
Early in our port, we established a standard set of
__future__ imports
and started incrementally converting files over to them, mainly because we
weren t yet sure what else to do and it seemed likely to be helpful.
absolute_import was definitely reasonable (and not often a problem in our
code), and print_function was annoying but necessary. In hindsight I m
not sure about unicode_literals, though. For files that only deal with
bytes and text it was reasonable enough, but as I mentioned above there were
also a number of cases where we needed literals of the language s native
str type, i.e. bytes in Python 2 and text in Python 3: this was
particularly noticeable in WSGI contexts, but also cropped up in some other
surprising
places. We
generally either omitted unicode_literals or used six.ensure_str in such
cases, but it was definitely a bit awkward and maybe I should have listened
more to people telling me it might be a bad idea.
A lot of Launchpad s early tests used
doctest, mainly in the
style
where you have text files that interleave narrative commentary with
examples. The development team later reached consensus that this was best
avoided in most cases, but by then there were far too many doctests to
conveniently rewrite in some other form. Porting doctests to Python 3 is
really annoying. You run into all the little changes in how objects are
represented as text (particularly u'...' versus '...', but plenty of
other cases as well); you have next to no tools to do anything useful like
skipping individual bits of a doctest that don t apply; using __future__
imports requires the rather obscure approach of adding the relevant names to
the doctest s globals in the relevant DocFileSuite or DocTestSuite;
dealing with many exception tracebacks requires something like
zope.testing.renormalizing;
and whatever code refactoring tools you re using probably don t work
properly. Basically, don t have done that. It did all turn out to be
tractable for us in the end, and I managed to avoid using much in the way of
fragile doctest extensions aside from the aforementioned
zope.testing.renormalizing, but it was not an enjoyable experience.
Regressions
I know of nine regressions that reached Launchpad s production systems as a
result of this porting work; of course there were various other regressions
caught by CI or in manual testing. (Considering the size of this project, I
count it as a resounding success that there were only nine production
issues, and that for the most part we were able to fix them quickly.)
Equality testing of removed database objects
One of the things we had to do while porting to Python 3 was to
implement
the __eq__, __ne__, and __hash__ special methods for all our database
objects. This was quite conceptually fiddly, because doing this requires
knowing each object s primary key, and that may not yet be available if
we ve created an object in Python but not yet flushed the actual INSERT
statement to the database (most of our primary keys are auto-incrementing
sequences). We thus had to take care to flush pending SQL statements in
such cases in order to ensure that we know the primary keys.
However, it s possible to have a problem at the other end of the object
lifecycle: that is, a Python object might still be reachable in memory even
though the underlying row has been DELETEd from the database. In most
cases we don t keep removed objects around for obvious reasons, but it can
happen in caching code, and buildd-manager
crashed as a result (in
fact while it was still running on Python 2). We had to take extra
care
to avoid this problem.
Debian imports crashed on non-UTF-8 filenames
Python 2 has some unfortunate
behaviour around passing
bytes or Unicode strings (depending on the platform) to shutil.rmtree, and
the combination of some porting
work
and a particular source package in Debian that contained a non-UTF-8 file
name caused us to run into this. The
fix
was to ensure that the argument passed to shutil.rmtree is a str
regardless of Python version.
We d actually run into something
similar
before: it s a subtle porting gotcha, since it s quite easy to end up
passing Unicode strings to shutil.rmtree if you re in the process of
porting your code to Python 3, and you might easily not notice if the file
names in your tests are all encoded using UTF-8.
lazr.restful ETags
We eventually got far enough along that we could switch one of our four
appserver machines (we have quite a number of other machines too, but the
appservers handle web and API requests) to Python 3 and see what happened.
By this point our extensive test suite had shaken out the vast majority of
the things that could go wrong, but there was always going to be room for
some interesting edge cases.
One of the Ubuntu kernel team reported that they were seeing an increase in
412 Precondition
Failed errors in some
of their scripts that use our webservice API. These can happen when you re
trying to modify an existing resource: the underlying protocol involves
sending an If-Match header with the ETag that the client thinks the
resource has, and if this doesn t match the ETag that the server calculates
for the resource then the client has to refresh its copy of the resource and
try again. We initially thought that this might be legitimate since it can
happen in normal operation if you collide with another client making changes
to the same resource, but it soon became clear that something stranger was
going on: we were getting inconsistent ETags for the same object even when
it was unchanged. Since we d recently switched a quarter of our appservers
to Python 3, that was a natural suspect.
Our lazr.restful package provides the framework for our webservice API,
and roughly speaking it generates ETags by serializing objects into some
kind of canonical form and hashing the result. Unfortunately the
serialization was dependent on the Python version in a few ways, and in
particular it serialized lists of strings such as lists of bug tags
differently: Python 2 used [u'foo', u'bar', u'baz'] where Python 3 used
['foo', 'bar', 'baz']. In lazr.restful 1.0.3 we switched to using
JSON
for this, removing the Python version dependency and ensuring consistent
behaviour between appservers.
Memory leaks
This problem took the longest to solve. We noticed fairly quickly from our
graphs that the appserver machine we d switched to Python 3 had a serious
memory leak. Our appservers had always been a bit leaky, but now it wasn t
so much a small hole that we can bail occasionally as the boat is sinking rapidly :
(Yes, this got in the way of working out what was going on with ETags for
a while.)
I spent ages messing around with various attempts to fix this. Since only
a quarter of our appservers were affected, and we could get by on 75%
capacity for a while, it wasn t urgent but it was definitely annoying.
After spending some quality time with
objgraph, for
some time I thought traceback reference
cycles
might be at fault, and I sent a number of fixes to various upstream projects
for those (e.g.
zope.pagetemplate).
Those didn t help the leaks much though, and after a while it became clear
to me that this couldn t be the sole problem: Python has a cyclic garbage
collector that will eventually collect reference cycles as long as there are
no strong references to any objects in them, although it might not happen
very quickly. Something else must be going on.
Debugging reference leaks in any non-trivial and long-running Python program
is extremely arduous, especially with ORMs that naturally tend to end up
with lots of cycles and caches. After a while I formed a hypothesis that
zope.server might be keeping a
strong reference to something, although I never managed to nail it down more
firmly than that. This was an attractive theory as we were already in the
process of migrating to Gunicorn for
other reasons anyway, and Gunicorn also has a convenient
max_requests
setting that s good at mitigating memory leaks. Getting this all in place
took some time, but once we did we found that everything was much more stable:
This isn t completely satisfying as we never quite got to the bottom of the
leak itself, and it s entirely possible that we ve only papered over it
using max_requests: I expect we ll gradually back off on how frequently we
restart workers over time to try to track this down. However,
pragmatically, it s no longer an operational concern.
Mirror prober HTTPS proxy handling
After we switched our script servers to Python 3, we had several reports of
mirror probing
failures. (Launchpad
keeps lists of Ubuntu archive and image mirrors, and probes them every so
often to check that they re reasonably complete and up to date.) This only
affected HTTPS mirrors when probed via a proxy server, support for which is
a relatively recent feature in Launchpad and involved some code that we
never managed to unit-test properly: of course this is exactly the code that
went wrong. Sadly I wasn t able to sort out that gap, but at least the
fix
was simple.
Non-MIME-encoded email headers
As I mentioned above, there were substantial changes in the email package
between Python 2 and 3, and indeed between minor versions of Python 3. Our
test coverage here is pretty good, but it s an area where it s very easy to
have gaps. We noticed that a script that processes incoming email was
crashing on messages with headers that were non-ASCII but not
MIME-encoded (and
indeed then crashing again when it tried to send a notification of the
crash!). The only examples of these I looked at were spam, but we still
didn t want to crash on them.
The
fix
involved being somewhat more careful about both the handling of headers
returned by Python s email parser and the building of outgoing email
notifications. This seems to be working well so far, although I wouldn t be
surprised to find the odd other incorrect detail in this sort of area.
Failure to handle non-ISO-8859-1 URL-encoded form input
Remember how I said that parsing HTTP form data was thorny? After we
finished upgrading all our appservers to Python 3, people started reporting
that they couldn t post Unicode comments to
bugs, which turned out
to be only if the attempt was made using JavaScript, and was because I
hadn t quite managed to get URL-encoded form data working properly with
zope.publisher and multipart. The current standard describes the
URL-encoded format for form data as in many ways an aberrant
monstrosity ,
so this was no great surprise.
Part of the problem was some very strange
choices in
zope.publisher dating back to 2004 or earlier, which I attempted to clean
up and simplify.
The rest was that Python 2 s urlparse.parse_qs unconditionally decodes
percent-encoded sequences as ISO-8859-1 if they re passed in as part of a
Unicode string, so multipart needs to work around
this on Python 2.
I m still not completely confident that this is correct in all situations,
but at least now that we re on Python 3 everywhere the matrix of cases we
need to care about is smaller.
Inconsistent marshalling of Loggerhead s disk cache
We use Loggerhead for providing web
browsing of Bazaar branches. When we upgraded one of its two servers to
Python 3, we immediately noticed that the one still on Python 2 was failing
to read back its revision information cache, which it stores in a database
on disk. (We noticed this because it caused a deployment to fail: when we
tried to roll out new code to the instance still on Python 2, Nagios checks
had already caused an incompatible cache to be written for one branch from
the Python 3 instance.)
This turned out to be a similar problem to the pickle issue mentioned
above, except this one was with marshal, which I didn t think to look for
because it s a relatively obscure module mostly used for internal purposes
by Python itself; I m not sure that Loggerhead should really be using it in
the first place. The fix was
relativelystraightforward,
complicated mainly by now needing to cope with throwing away unreadable
cache data.
Ironically, if we d just gone ahead and taken the nominally riskier path of
upgrading both servers at the same time, we might never have had a problem here.
Intermittent bzr failures
Finally, after we upgraded one of our two Bazaar codehosting servers to
Python 3, we had a
report of intermittent
bzr branch hangs. After some digging I found this in our logs:
Traceback (most recent call last):...
File "/srv/bazaar.launchpad.net/production/codehosting1-rev-20124175fa98fcb4b43973265a1561174418f4bd/env/lib/python3.5/site-packages/twisted/conch/ssh/channel.py", line 136, in addWindowBytesself.startWriting()
File "/srv/bazaar.launchpad.net/production/codehosting1-rev-20124175fa98fcb4b43973265a1561174418f4bd/env/lib/python3.5/site-packages/lazr/sshserver/session.py", line 88, in startWritingresumeProducing()
File "/srv/bazaar.launchpad.net/production/codehosting1-rev-20124175fa98fcb4b43973265a1561174418f4bd/env/lib/python3.5/site-packages/twisted/internet/process.py", line 894, in resumeProducingforpinself.pipes.itervalues():builtins.AttributeError: 'dict' object has no attribute 'itervalues'
I d seen this before in our git hosting service: it was a bug in Twisted s
Python 3 port, fixed after
20.3.0 but unfortunately after the last release that supported Python 2, so
we had to backport that patch. Using the same backport dealt with this.
Onwards!
I'm creating a program that uses the web browser for its user interface, and
I'm reasonably sure I'm not the first person doing this.
Normally such a problem would listen to a port on localhost, and tell the
browser to connect to it. Bonus points for
listening to a randomly allocated free port,
so that one does not need to involve some amount of luck to get the program
started.
However, using a local port still means that any user on the local machine can
connect to it, which is generally a security issue.
A possible solution would be to use AF_UNIX Unix Domain Sockets, which are
supported by various web servers, but as far as I understand not currently by
browsers. I checked Firefox and Chrome,
and they currently seem to fail to even acknowledge the use case.
I'm reasonably sure I'm not the first person doing this, and yes, it's intended
as an understatement.
So, dear Lazyweb, is there a way to securely use a browser as a UI for a
user's program, without exposing access to the backend to other users in the
system?
Access token in the URL
Emanuele Di Giacomo suggests to add an access
token to the URL that gets passed to the browser.
This would work to protect access on localhost: even if the application cannot
use HTTPS, other users cannot see packets that go through the local interface,
so both the access token and the session cookie that one could send afterwards
would be protected.
Network namespaces
I thought about isolating server and browser in a private network namespace
with something like unshare(1), but it seems to require root.
Johannes Schauer Marin Rodrigues wrote to correct that:
It's possible to unshare the network namespace by first unsharing the user
namespace and thus becoming root which is possible without being root since
#898446 got fixed.
For example you can run this as the normal user:
lxc-usernsexec -- lxc-unshare -s NETWORK -- ip addr
If you don't want to depend on lxc, you can write a wrapper in Perl or Python.
I have a Perl implementation of that in mmdebstrap.
Firewalling
Martin Schuster wrote to suggest another option:
I had the same issue. My approach was "weird", but worked:
Block /outgoing/ connections to the port, unless the uid is correct.
That might be counter-intuitive, but of course all connections
/to/ localhost will be done /from/ localhost also.
Something like:
iptables -A OUTPUT -p tcp -d localhost --dport 8123 -m owner --uid-owner joe -j ACCEPTiptables -A OUTPUT -p tcp -d localhost --dport 8123 -j REJECT
A new minor release of our ttdo package arrived on CRAN today. The ttdo package extends the most excellent (and very minimal / zero depends) unit testing package tinytest by Mark van der Loo with the very clever and well-done diffobj package by Brodie Gaslam to give us test results with visual diffs (as shown in the screenshot here) which seemingly is so compelling an idea that another package decided to copied it more recently:
This release is mostly procedural to accomodate changes in tinytest 1.3.1 released today, and brought to us via a pull request by Mark himself. Other than that we also updated the CI runner to use r-ci and accomodated new CRAN check for a superfluous LazyData: field in a package without a data/ directory.
This release also gets another #ThankYouCRAN mark as it was once again fully automated and intervention-free (once the new tinytest release hit CRAN).
As usual, the NEWS entry follows.
Changes in ttdo version 0.0.7 (2021-07-06)
The CI setup was updated to use run.sh from r-ci (Dirk).
The package was updated for an API extension in tinytest 1.3.1 or later (Mark van der Look in #7)
The unused LazyData field was removed from DESCRIPTION (Dirk)
WebP and AVIF are two image formats for the web. They aim to produce
smaller files than JPEG and PNG. They both support lossy and lossless
compression, as well as alpha transparency. WebP was developed by
Google and is a derivative of the VP8 video format.1 It
is supported on most browsers. AVIF is using the newer AV1
video format to achieve better results. It is supported by
Chromium-based browsers and has experimental support for
Firefox.2
Your browser supports WebP and AVIF image formats.Your browser supports none of these image formats.Your browser only supports the WebP image format.Your browser only supports the AVIF image format.
Without JavaScript, I can t tell what your browser supports.
Converting and optimizing images
For this blog, I am using the following shell snippets to convert and
optimize JPEG and PNG images. Skip to the next
section if you are only interested in
the Nginx setup.
JPEG images
JPEG images are converted to WebP using cwebp.
PNG images
PNG images are down-sampled to 8-bit RGBA-palette using
pngquant. The conversion reduces file sizes significantly while
being mostly invisible.
No conversion is done to AVIF: lossless compression is not as
efficient as pngquant and lossy compression is only marginally
better than what I get with WebP.
Keeping only the smallest files
I am only keeping WebP and AVIF images if they are at least 10%
smaller than the original format: decoding is usually faster for JPEG
and PNG; and JPEG images can be decoded progressively.3
for f in media/images/**/*.webp,avif;doorig=$(stat --format %s $ f%.*)new=$(stat --format %s $f)(( orig*0.90 > new )) rm $fdone
I only keep AVIF images if they are smaller than WebP.
for f in media/images/**/*.avif;do[[ -f $ f%.*.webp ]]continueorig=$(stat --format %s $ f%.*.webp)new=$(stat --format %s $f)(($orig > $new)) rm $fdone
We can compare how many images are kept when converted to WebP or AVIF:
printf" %10s %10s %10s\n" Original WebP AVIF
for format in png jpg;doprintf" $ format:u %10s %10s %10s\n"\$(find media/images -name "*.$format" wc -l)\$(find media/images -name "*.$format.webp" wc -l)\$(find media/images -name "*.$format.avif" wc -l)done
AVIF is better than MozJPEG for most JPEG files while WebP beats
MozJPEG only for one file out of two:
Original WebP AVIF
PNG 64 47 0
JPG 83 40 74
Further reading
I didn t detail my choices for quality parameters and there is not
much science in it. Here are two resources providing more insight on
AVIF:
For example, let s suppose the browser requests
/images/ont-box-orange@2x.jpg. If it supports WebP but not AVIF,
$webp_suffix is set to .webp while $avif_suffix is set to the
empty string. The server tries to serve the first existing file in
this list:
/images/ont-box-orange@2x.jpg.webp
/images/ont-box-orange@2x.jpg
/images/ont-box-orange@2x.jpg.webp
/images/ont-box-orange@2x.jpg
If the browser supports both AVIF and WebP, Nginx walks the following
list:
/images/ont-box-orange@2x.jpg.webp.avif (it never exists)
Progressive decoding is not planned for WebP but could
be implemented using low-quality thumbnail images for AVIF. See
this issue for a discussion.
The Vary header ensures an intermediary cache (a proxy
or a CDN) checks the Accept header before using a cached
response. Internet Explorer has trouble with this header and may
not be able to cache the resource properly. There is a
workaround but Internet Explorer s market share is now so
small that it is pointless to implement it.
The Horse and His Boy was the fifth published book in the
Chronicles of Narnia, but it takes place during the last chapter of
The Lion, the Witch and the Wardrobe, in
the midst of the golden age of Narnia. It's the only true side story of
the series and it doesn't matter much where in sequence you read it, as
long as it's after The Lion, the Witch and the Wardrobe and before
The Last Battle (which would spoil its ending somewhat).
MAJOR SPOILERS BELOW.
The Horse and His Boy is also the only book of the series that is
not a portal fantasy. The Pevensie kids make an appearance, but as the
ruling kings and queens of Narnia, and only as side characters. The
protagonists are a boy named Shasta, a girl named Aravis, and horses named
Bree and Hwin. Aravis is a Calormene, a native of the desert (and
extremely Orientalist, but more on that later) kingdom to the south of
Narnia and Archenland. Shasta starts the book as the theoretically
adopted son but mostly slave of a Calormene fisherman. The Horse
and His Boy is the story of their journey from Calormen north to
Archenland and Narnia, just in time to defend Narnia and Archenland from
an invasion.
This story starts with a great hook. Shasta's owner is hosting a passing
Tarkaan, a Calormene lord, and overhears a negotiation to sell Shasta to
the Tarkaan as his slave (and, in the process, revealing that he rescued
Shasta as an infant from a rowboat next to a dead man). Shasta starts
talking to the Tarkaan's horse and is caught by surprise when the horse
talks back. He is a Talking Horse from Narnia, kidnapped as a colt, and
eager to return to Narnia and the North. He convinces Shasta to attempt
to escape with him.
This has so much promise. For once, we're offered a story where one of
the talking animals of Narnia is at least a co-protagonist and has some
agency in the story. Bree takes charge of Shasta, teaches him to ride
(or, mostly, how to fall off a horse), and makes most of the early plans.
Finally, a story that recognizes that Narnia stories don't have to revolve
around the humans!
Unfortunately, Bree is an obnoxious, arrogant character. I wanted to like
him, but he makes it very hard. This gets even worse when Shasta is
thrown together with Aravis, a noble Calormene girl who is escaping an
arranged marriage on her own talking mare, Hwin. Bree is a warhorse, Hwin
is a lady's riding mare, and Lewis apparently knows absolutely nothing
about horses, because every part of Bree's sexist posturing and Hwin's
passive meekness is awful and cringe-worthy. I am not a horse person, so
will link to
Judith Tarr's much more knowledgeable critique at Tor.com, but suffice
it to say that mares are not meekly deferential or awed by
stallions. If Bree had behaved that way with a real mare, he would have
gotten the crap beaten out of him (which might have improved his attitude
considerably). As is, we have to put up with rather a lot of Bree's
posturing and Hwin (who I liked much better) barely gets a line and acts
disturbingly like she was horribly abused.
This makes me sad, because I like Bree's character arc. He's spent his
whole life being special and different from those around him, and while he
wants to escape this country and return home, he's also gotten used to
being special. In Narnia, he will just be a normal talking horse. To get
everything else he wants, he also has to let go of the idea that he's
someone special. If Lewis had done more with this and made Bree a more
sympathetic character, this could have been very effective. As written,
it only gets a few passing mentions (mostly via Bree being weirdly
obsessed with whether talking horses roll) and is therefore overshadowed
by Shasta's chosen one story and Bree's own arrogant behavior.
The horses aside, this is a passable adventure story with some well-done
moments. The two kids and their horses end up in Tashbaan, the huge
Calormene capital, where they stumble across the Narnians and Shasta is
mistaken for one of their party. Radagast, the prince of Calormen, is
proposing marriage to Susan, and the Narnians are in the process of
realizing he doesn't plan to take no for an answer. Aravis, meanwhile,
has to sneak out of the city via the Tisroc's gardens, which results in
her hiding behind a couch as she hears Radagast's plans to invade
Archenland and Narnia to take Susan as his bride by force. Once reunited,
Shasta, Aravis, and the horses flee across the desert to bring warning to
Archenland and then Narnia.
Of all the Narnia books, The Horse and His Boy leans the hardest
into the personal savior angle of Christianity. Parts of it, such as
Shasta's ride over the pass into Narnia, have a strong
"Footprints" feel
to them. Most of the events of the book are arranged by Aslan, starting
with Shasta's early life. Readers of the series will know this when a
lion shows up early to herd the horses where they need to go, or when a
cat keeps Shasta company in the desert and frightens away jackals. Shasta
only understands near the end.
I remember this being compelling stuff as a young Christian reader. This
personal attention and life shaping from God is pure Christian wish
fulfillment of the "God has a plan for your life" variety, even more so
than Shasta turning out to be a lost prince. As an adult re-reader, I can
see that Lewis is palming the
theodicy card rather
egregiously. It's great that Aslan was making everything turn out well in
the end, but why did he have to scare the kids and horses half to death in
the process? They were already eager to do what he wanted, but it's
somehow inconceivable that Aslan would simply tell them what to do rather
than manipulate them. There's no obvious in-story justification why he
couldn't have made the experience much less terrifying. Or, for that
matter, prevented Shasta from being kidnapped as an infant in the first
place and solved the problem of Radagast in a more direct way. This sort
of theology takes as an unexamined assumption that a deity must refuse to
use his words and instead do everything in weirdly roundabout and
mysterious ways, which makes even less sense in Narnia than in our world
given how directly and straightforwardly Aslan has acted in previous
books.
It was also obvious to me on re-read how unfair Lewis's strict gender
roles are to Aravis. She's an excellent rider from the start of the book
and has practiced many of the things Shasta struggles to do, but Shasta is
the boy and Aravis is the girl, so Aravis has to have girl adventures
involving tittering princesses, luxurious baths, and eavesdropping behind
couches, whereas Shasta has boy adventures like riding to warn the king or
bringing word to Narnia. There's nothing very objectionable about Shasta
as a character (unlike Bree), but he has such a generic character arc.
The Horse and Her Girl with Aravis and Hwin as protagonists would
have been a more interesting story, and would have helpfully complicated
the whole Narnia and the North story motive.
As for that storyline, wow the racism is strong in this one, starting with
the degree that The Horse and His Boy is deeply concerned with
people's skin color. Shasta is white, you see, clearly marking him as
from the North because all the Calormenes are dark-skinned. (This makes
even less sense in this fantasy world than in our world because it's
strongly implied in The Magician's Nephew that all the humans in
Calormen came from Narnia originally.) The Calormenes all talk like
characters from bad translations of the Arabian Nights and are shown as
cruel, corrupt slavers with a culture that's a Orientalist mishmash of
Arab, Persian, and Chinese stereotypes. Everyone is required to say "may
he live forever" after referencing the Tisroc, which is an obvious and
crude parody of Islam. This stereotype fest culminates in the incredibly
bizarre scene that Aravis overhears, in which the grand vizier literally
grovels on the floor while Radagast kicks him and the Tisroc, Radagast's
father, talks about how Narnia's freedom offends him and the barbarian
kingdom would be more profitable and orderly when conquered.
The one point to Lewis's credit is that Aravis is also Calormene, tells
stories in the same style, and is still a protagonist and just as
acceptable to Aslan as Shasta is. It's not enough to overcome the
numerous problems with Lewis's lazy world-building, but it makes me wish
even more that Aravis had gotten her own book and more meaningful scenes
with Aslan.
I had forgotten that Susan appears in this book, although that appearance
doesn't add much to the general problem of Susan in Narnia except perhaps
to hint at Lewis's later awful choices. She is shown considering marriage
to the clearly villainous Radagast, and then only mentioned later with a
weird note that she doesn't ride to war despite being the best archer of
the four. I will say again that it's truly weird to see the Pevensie kids
as (young) adults discussing marriage proposals, international politics,
and border wars while remembering they all get dumped back into their
previous lives as British schoolkids. This had to have had dramatic
effects on their lives that Lewis never showed. (I know, the real answer
is that Lewis is writing these books according to childhood imaginary
adventure logic, where adventures don't have long-term consequences of
that type.)
I will also grumble once more at how weirdly ineffectual Narnians are
until some human comes to tell them what to do. Calormen is obviously a
threat; Susan just escaped from an attempted forced marriage. Archenland
is both their southern line of defense and is an ally separated by a
mountain pass in a country full of talking eagles, among other obvious
messengers. And yet, it falls to Shasta to ride to give warning because
he's the human protagonist of the story. Everyone else seems to be too
busy with quirky domesticity or endless faux-medieval chivalric parties.
The Horse and His Boy was one of my favorites when I was a kid, but
reading as an adult I found it much harder to tolerate Bree or read past
the blatant racial and cultural stereotyping. The bits with Aslan also
felt less magical to me than they did as a kid because I was asking more
questions about why Aslan had to do everything in such an opaque and
perilous way. It's still not a bad adventure; Aravis is a great
character, the bits in Tashbaan are at least memorable, and I still love
the Hermit of the Southern March and want to know more about him. But I
would rank it below the top tier of Narnia books, alongside
Prince Caspian as a book with some great
moments and some serious flaws.
Followed in original publication order by The Magician's Nephew.
Rating: 7 out of 10
My newsletter Le Courrier du hacker (3,800 subscribers, 176 issues) is 3 years old and Mailchimp costs were becoming unbearable for a small project ($50 a month, $600 a year), with still limited revenues nowadays. Switching to the Open Source Mailtrain plugged to the AWS Simple Email Service (SES) will dramatically reduce the associated costs.
First things first, thanks a lot to Pierre-Gilles Leymarie for his own article about switching to Mailtrain/SES. I owe him (and soon you too) so much. This article will be a step-by-step about how to set up Mailtrain/SES on a dedicated server running Linux.
What s the purpose of this article?
Mailchimp is more and more expensive following the growth of your newsletter subscribers and you need to leave it. You can use Mailtrain, a web app running on your own server and use the AWS SES service to send emails in an efficient way, avoiding to be flagged as a spammer by the other SMTP servers (very very common, you can try but you have been warned against
Prerequisites
You will need the following prerequisites :
An AWS account with admin rights
Full control over the domain name you use to send your newsletter
A baremetal or virtual Linux Debian server you have the root access to
NodeJS installed (8x and 10x are ok with Mailtrain)
A MySQL/MariaDB instance with the root access to
Redis 3x (not 5) if you want to use Redis (not mandatory)
Steps
This is a fairly straightforward setup if you know what you re doing. In the other case, you may need the help of a professional sysadmin.
You will need to complete the following steps in order to complete your setup:
Configure AWS SES
Configure your server by:
configuring your database
install Mailtrain
configuring your web server
Configure your Mailtrain setup
Configure AWS SES
Verify your domain
You need to configure the DKIM to certify that the emails sent are indeed from your own domain. DKIM is mandatory, it s the de-facto standard in the mail industry.
Ask to verify your domain
Ask AWS SES to verify a domain
Generate the DKIM settings
Generate the DKIM settings
Use the DKIM settings
Now you have your DKIM settings and Amazon AWS is waiting for finding the TXT field in your DNS zone.
Configure your DNS zone to include DKIM settings
I can t be too specific for this section because it varies A LOT depending on your DNS provider. The keys is: as indicated by the previous image you have to create one TXT record and two CNAME records in your DNS zone. The names, the types and the values are indicated by AWS SES.
If you don t understand what s going here, there is a high probabiliy you ll need a system administrator to apply these modifications and the next ones in this article.
Am I okay for AWS SES ?
As long as the word verified does not appear for your domain, as shown in the image below, something is wrong. Don t wait too long, you have a misconfiguration somewhere.
AWS SES pending verification
When your domain is verified, you ll also receive an email to inform you about the successful verification.
SMTP settings
The last step is generating your credentials to use the AWS SES SMTP server. IT is really straightforward, providing the STMP address to use, the port, and a pair of username/password credentials.
AWS SES SMTP settings and credentials
Just click on Create My SMTP Credentials and follow the instructions. Write the SMTP server address somewhere and store the file with credentials on your computer, we ll need them below.
Configure your server
As we said before, we need a baremetal server or a virtual machine running a recent Linux.
Configure your MySQL/MariaDB database
We create a user mailtrain having all rights on a new database mailtrain.
MariaDB [(none)]> create database mailtrain;
Query OK, 1 row affected (0.00 sec)
MariaDB [(none)]> CREATE USER 'mailtrain' IDENTIFIED BY 'V3rYD1fF1cUlTP4sSW0rd!';
Query OK, 0 rows affected (0.01 sec)
MariaDB [(none)]> GRANT ALL PRIVILEGES ON mailtrain.* TO 'mailtrain'@localhost IDENTIFIED BY 'V3rYD1fF1cUlTP4sSW0rd!';
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> show databases;
+--------------------+
Database
+--------------------+
information_schema
mailtrain
mysql
performance_schema
+--------------------+
6 rows in set (0.00 sec)
MariaDB [(none)]> Bye
Configure your web server
I use Nginx and I ll give you the complete setup for it, including generating Let s Encrypt.
Configure Let s Encrypt
You need to stop Nginx as root:
systemctl stop nginx
Then get the certificate only, I ll give the Nginx Vhost configuration:
certbot certonly -d mailtrain.toto.com
Install Mailtrain
On your server create the following directory:
mkdir -p /var/www/ cd /var/www wget https://github.com/Mailtrain-org/mailtrain/archive/refs/tags/v1.24.1.tar.gz tar zxvf v1.24.1.tar.gz
Modify the file /var/www/mailtrain/config/production.toml to use the MySQL settings:
Now Mailtrain is launched and should be running. Yeah I know it s ugly to launch like this (root process in a screen, etc) you can improve security with the following commands:
To register the following systemd unit and to launch the new Mailtrain daemon, use the following commands (do not forget to kill your screen session if you used it before):
Now Mailtrain is running under the classic user mailtrain of the mailtrain system group.
Configure the Nginx Vhost configuration for your domain
Here is my configuration for the Mailtrain Nginx Vhost:
This Nginx vhost will redirect all http requests coming to the Mailtrain process running on the 3000 port. Now it s time to setup Mailtrain!
Setup Mailtrain
You should be able to access your Mailtrain at https://mailtrain.toto.com
Mailtrain is quite simple to configure, Here is my mailer setup. Mailtrain just forwards emails to AWS SES. We only have to plug Mailtrain to AWS SES.
Mailtrain mailer setup
The hostname is provided by AWS SES in the STMP Settings section. Use the 465 port and USE TLS option. Next is providing your AWS SES username and password you generated above and stored somewhere on your computer.
One of the issues I encountered is the AWS SES rate limit. Send too many emails too fast will get you flagged as a spammer.
So I had to throttle Mailtrain. Because I m a lazy man, I asked Pierre-Gilles Leymarie his setup. Quite easier than determining myself the good one. Here is my setup. Works fine for my soon-to-be 4k subscribers. The idea is: if your AWS SES lets you know you send too fast then just slow down.
Mailtrain to throttle sending emails to AWS SES
Conclusion
That s it! You re ready! Almost. You need an HTML template for your newsletter and a list of subscribers. Buf if you re not new in the newsletter field, fleeing Mailchimp because of their expensive prices, you should have them both already.
After sending almost ten issues with this setup, I m really happy with it. Open/click rates are the same.
When leaving Mailchimp, do not leave any list of subscribers because they ll charge you $8 for a 0 to 500 contacts, that s crazy expensive!
About the author
The Debian Janitor is an automated
system that commits fixes for (minor) issues in Debian packages that can be
fixed by software. It gradually started proposing merges in early
December. The first set of changes sent out ran lintian-brush on sid packages maintained in
Git. This post is part of a series about the progress of the Janitor.
The FOSS world uses a wide variety of different build tools; given a git
repository or tarball, it can be hard to figure out how to build and install a
piece of software.
Humans will generally know what build tool a project is using when they check
out a project from git, or they can read the README. And even then, the answer
may not always be straightforward to everybody. For automation, there
is no obvious place to figure out how to build or install a project.
Debian
For Debian packages, Debian maintainers generally will have determined
that the appropriate tools to invoke are, and added appropriate invocations to
debian/rules. This is really nice when rebuilding all of Debian - one can just
invoke debian/rules - a consistent interface - and it will in turn invoke the
right tools to build the package, meeting a long list of requirements.
With newer versions of debhelper
and most common build systems, debhelper can figure a lot of this out
automatically - the maintainer just has to add the
appropriate build and run time dependencies.
However, debhelper needs to be consistent in its behaviour per compat level -
otherwise builds might start failing with different versions of debhelper, when
the autodetection logic is changed. debhelper can also only do the right thing
if all the necessary dependencies are present. debhelper also only functions
in the context of a Debian package.
Ognibuild
Ognibuild is a new tool that figures
out the build system in use by an upstream project, as well as the other
dependencies it needs. This information can then be used to invoke said build
system, or to e.g. add missing build dependencies to a Debian package.
Ognibuild uses a variety of techniques to work out what the dependencies for an
upstream package are:
Extracting dependencies and other requirements declared in build system
metadata (e.g. setup.py)
Attempting builds and parsing build logs for missing dependencies (repeating
until the build succeeds), calling out to buildlog-consultant
Once it is determined which dependencies are missing, they can be resolved in a
variety of ways. Apt can be invoked to install missing dependencies on Debian
systems (optionally in a chroot) or ecosystem-specific tools can be used to do
so (e.g. pypi or cpan).
Instead of installing packages, the tool can also simply
inform the user about the missing packages and commands to install them, or
update a Debian package appropriately (this is what deb-fix-build does).
The target audience of ognibuild are people who need to (possibly from
automation) build a variety of projects from different ecosystems or users who
are looking to just install a project from source. Developers who are just
hacking on e.g. a Python project are better off directly invoking the
ecosystem-native tools rather than a wrapper like ognibuild.
Supported ecosystems
(Partially) supported ecosystems currently include:
Combinations of make and autoconf, automake or CMake
Python, including fetching packages from pypi
Perl, including fetching packages from cpan
Haskell, including fetching from hackage
Ninja/Meson
Maven
Rust, including fetching packages from crates.io
PHP Pear
R, including fetching packages from CRAN and Bioconductor
Usage
Ognibuild provides a couple of top-level subcommands that will seem familiar to anybody who has used a couple of other build systems:
ogni clean - remove build artifacts
ogni dist - create a dist tarball
ogni build - build the project in the current directory
ogni test - run the test suite
ogni install - install the project somewhere
ogni info - display project information including discovered build system and dependencies
ogni exec - run an arbitrary command but attempt to resolve issues like missing dependencies
These tools all take a couple of common options:
resolve=apt auto native
Specifies how to resolve any missing dependencies:
apt: install the appropriate dependency using apt
native: install dependencies using native tools like pip or cpan
auto: invoke either apt or native package install, depending on whether
the current user is allowed to invoke apt
schroot=name
Run inside of a schroot.
explain
do not make any changes but tell the user which native on apt packages they could install.
There are also subcommand-specific options, e.g. to install to a specific directory on restrict which tests are run.
Examples
Creating a dist tarball
1
2
3
4
5
6
7
8
9
% git clone https://github.com/dulwich/dulwich
%cd dulwich
% ogni --schroot=unstable-amd64-sbuild dist
Writing dulwich-0.20.21/setup.cfgcreating distCreating tar archiveremoving 'dulwich-0.20.21' (and everything under it)Found new tarball dulwich-0.20.21.tar.gz in /var/run/schroot/mount/unstable-amd64-sbuild-974d32d7-6f10-4e77-8622-b6a091857e85/build/tmpucazj7j7/package/dist.
Installing ldb from source, resolving dependencies using apt
% wget https://cpan.metacpan.org/authors/id/T/TO/TORU/XML-LibXML-LazyBuilder-0.08.tar.gz_ <https://cpan.metacpan.org/authors/id/T/TO/TORU/XML-LibXML-LazyBuilder-0.08.tar.gz>_
% tar xvfz XML-LibXML-LazyBuilder-0.08.tar.gz
Cd XML-LibXML-LazyBuilder-0.08% ogni test
Current Status
ognibuild is still in its early stages, but works well enough that it can
detect and invoke the build system for most of the upstream projects packaged
in Debian. If there are buildsystems that it currently lacks support for or
other issues, then I d welcome any bug reports.
Previously in George Orwell travel posts: Sutton Courtenay, Marrakesh, Hampstead, Paris, Southwold & The River Orwell.
Wallington is a small village in Hertfordshire, approximately fifty miles north of London and twenty-five miles from the outskirts of Cambridge. George Orwell lived at No. 2 Kits Lane, better known as 'The Stores', on a mostly-permanent basis from 1936 to 1940, but he would continue to journey up from London on occasional weekends until 1947.
His first reference to The Stores can be found in early 1936, where Orwell wrote from Lancashire during research for The Road to Wigan Pier to lament that he would very much like "to do some work again impossible, of course, in the [current] surroundings":
I am arranging to take a cottage at Wallington near Baldock in Herts, rather a pig in a poke because I have never seen it, but I am trusting the friends who have chosen it for me, and it is very cheap, only 7s. 6d. a week [ 20 in 2021].
For those not steeped in English colloquialisms, "a pig in a poke" is an item bought without seeing it in advance. In fact, one general insight that may be drawn from reading Orwell's extant correspondence is just how much he relied on a close network of friends, belying the lazy and hagiographical picture of an independent and solitary figure. (Still, even Orwell cultivated this image at times, such as in a patently autobiographical essay he wrote in 1946. But note the off-hand reference to varicose veins here, for they would shortly re-appear as a symbol of Winston's repressed humanity in Nineteen Eighty-Four.)
Nevertheless, the porcine reference in Orwell's idiom is particularly apt, given that he wrote the bulk of Animal Farm at The Stores his 1945 novella, of course, portraying a revolution betrayed by allegorical pigs. Orwell even drew inspiration for his 'fairy story' from Wallington itself, principally by naming the novel's farm 'Manor Farm', just as it is in the village. But the allusion to the purchase of goods is just as appropriate, as Orwell returned The Stores to its former status as the village shop, even going so far as to drill peepholes in a door to keep an Orwellian eye on the jars of sweets. (Unfortunately, we cannot complete a tidy circle of references, as whilst it is certainly Napoleon Animal Farm's substitute for Stalin who is quoted as describing Britain as "a nation of shopkeepers", it was actually the maraisardBertrand Bar re who first used the phrase).
"It isn't what you might call luxurious", he wrote in typical British understatement, but Orwell did warmly emote on his animals. He kept hens in Wallington (perhaps even inspiring the opening line of Animal Farm: "Mr Jones, of the Manor Farm, had locked the hen-houses for the night, but was too drunk to remember to shut the pop-holes.") and a photograph even survives of Orwell feeding his pet goat, Muriel. Orwell's goat was the eponymous inspiration for the white goat in Animal Farm, a decidedly under-analysed character who, to me, serves to represent an intelligentsia that is highly perceptive of the declining political climate but, seemingly content with merely observing it, does not offer any meaningful opposition. Muriel's aesthetic of resistance, particularly in her reporting on the changes made to the Seven Commandments of the farm, thus rehearses the well-meaning (yet functionally ineffective) affinity for 'fact checking' which proliferates today. But I digress.
There is a tendency to "read Orwell backwards", so I must point out that Orwell wrote several other works whilst at The Stores as well. This includes his Homage to Catalonia, his aforementioned The Road to Wigan Pier, not to mention countless indispensable reviews and essays as well. Indeed, another result of focusing exclusively on Orwell's last works is that we only encounter his ideas in their highly-refined forms, whilst in reality, it often took many years for concepts to fully mature we first see, for instance, the now-infamous idea of "2 + 2 = 5" in an essay written in 1939.
This is important to understand for two reasons. Although the ostentatiously austere Barnhill might have housed the physical labour of its writing, it is refreshing to reflect that the philosophical heavy-lifting of Nineteen Eighty-Four may have been performed in a relatively undistinguished North Hertfordshire village. But perhaps more importantly, it emphasises that Orwell was just a man, and that any of us is fully capable of equally significant insight, with to quote Christopher Hitchens "little except a battered typewriter and a certain resilience."
The red commemorative plaque not only limits Orwell's tenure to the time he was permanently in the village, it omits all reference to his first wife, Eileen O'Shaughnessy, whom he married in the village church in 1936.Wallington's Manor Farm, the inspiration for the farm in Animal Farm. The lower sign enjoins the public to inform the police "if you see anyone on the [church] roof acting suspiciously". Non-UK-residents may be surprised to learn about the systematic theft of lead.
It all started with the big bang! We nearly lost 33 of 36 disks on a Proxmox/Ceph Cluster; this is the story of how we recovered them.
At the end of 2020, we eventually had a long outstanding maintenance window for taking care of system upgrades at a customer. During this maintenance window, which involved reboots of server systems, the involved Ceph cluster unexpectedly went into a critical state. What was planned to be a few hours of checklist work in the early evening turned out to be an emergency case; let s call it a nightmare (not only because it included a big part of the night). Since we have learned a few things from our post mortem and RCA, it s worth sharing those with others. But first things first, let s step back and clarify what we had to deal with.
The system and its upgrade
One part of the upgrade included 3 Debian servers (we re calling them server1, server2 and server3 here), running on Proxmox v5 + Debian/stretch with 12 Ceph OSDs each (65.45TB in total), a so-called Proxmox Hyper-Converged Ceph Cluster.
First, we went for upgrading the Proxmox v5/stretch system to Proxmox v6/buster, before updating Ceph Luminous v12.2.13 to the latest v14.2 release, supported by Proxmox v6/buster. The Proxmox upgrade included updating corosync from v2 to v3. As part of this upgrade, we had to apply some configuration changes, like adjust ring0 + ring1 address settings and add a mon_host configuration to the Ceph configuration.
During the first two servers reboots, we noticed configuration glitches. After fixing those, we went for a reboot of the third server as well. Then we noticed that several Ceph OSDs were unexpectedly down. The NTP service wasn t working as expected after the upgrade. The underlying issue is a race condition of ntp with systemd-timesyncd (see #889290). As a result, we had clock skew problems with Ceph, indicating that the Ceph monitors clocks aren t running in sync (which is essential for proper Ceph operation). We initially assumed that our Ceph OSD failure derived from this clock skew problem, so we took care of it. After yet another round of reboots, to ensure the systems are running all with identical and sane configurations and services, we noticed lots of failing OSDs. This time all but three OSDs (19, 21 and 22) were down:
% sudo ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 65.44138 root default
-2 21.81310 host server1
0 hdd 1.08989 osd.0 down 1.00000 1.00000
1 hdd 1.08989 osd.1 down 1.00000 1.00000
2 hdd 1.63539 osd.2 down 1.00000 1.00000
3 hdd 1.63539 osd.3 down 1.00000 1.00000
4 hdd 1.63539 osd.4 down 1.00000 1.00000
5 hdd 1.63539 osd.5 down 1.00000 1.00000
18 hdd 2.18279 osd.18 down 1.00000 1.00000
20 hdd 2.18179 osd.20 down 1.00000 1.00000
28 hdd 2.18179 osd.28 down 1.00000 1.00000
29 hdd 2.18179 osd.29 down 1.00000 1.00000
30 hdd 2.18179 osd.30 down 1.00000 1.00000
31 hdd 2.18179 osd.31 down 1.00000 1.00000
-4 21.81409 host server2
6 hdd 1.08989 osd.6 down 1.00000 1.00000
7 hdd 1.08989 osd.7 down 1.00000 1.00000
8 hdd 1.63539 osd.8 down 1.00000 1.00000
9 hdd 1.63539 osd.9 down 1.00000 1.00000
10 hdd 1.63539 osd.10 down 1.00000 1.00000
11 hdd 1.63539 osd.11 down 1.00000 1.00000
19 hdd 2.18179 osd.19 up 1.00000 1.00000
21 hdd 2.18279 osd.21 up 1.00000 1.00000
22 hdd 2.18279 osd.22 up 1.00000 1.00000
32 hdd 2.18179 osd.32 down 1.00000 1.00000
33 hdd 2.18179 osd.33 down 1.00000 1.00000
34 hdd 2.18179 osd.34 down 1.00000 1.00000
-3 21.81419 host server3
12 hdd 1.08989 osd.12 down 1.00000 1.00000
13 hdd 1.08989 osd.13 down 1.00000 1.00000
14 hdd 1.63539 osd.14 down 1.00000 1.00000
15 hdd 1.63539 osd.15 down 1.00000 1.00000
16 hdd 1.63539 osd.16 down 1.00000 1.00000
17 hdd 1.63539 osd.17 down 1.00000 1.00000
23 hdd 2.18190 osd.23 down 1.00000 1.00000
24 hdd 2.18279 osd.24 down 1.00000 1.00000
25 hdd 2.18279 osd.25 down 1.00000 1.00000
35 hdd 2.18179 osd.35 down 1.00000 1.00000
36 hdd 2.18179 osd.36 down 1.00000 1.00000
37 hdd 2.18179 osd.37 down 1.00000 1.00000
Our blood pressure increased slightly! Did we just lose all of our cluster? What happened, and how can we get all the other OSDs back?
We stumbled upon this beauty in our logs:
The same issue was present for the other failing OSDs. We hoped, that the data itself was still there, and only the mounting of the XFS partitions failed. The Ceph cluster was initially installed in 2017 with Ceph jewel/10.2 with the OSDs on filestore (nowadays being a legacy approach to storing objects in Ceph). However, we migrated the disks to bluestore since then (with ceph-disk and not yet via ceph-volume what s being used nowadays). Using ceph-disk introduces these 100MB XFS partitions containing basic metadata for the OSD.
Given that we had three working OSDs left, we decided to investigate how to rebuild the failing ones. Some folks on #ceph (thanks T1, ormandj + peetaur!) were kind enough to share how working XFS partitions looked like for them. After creating a backup (via dd), we tried to re-create such an XFS partition on server1. We noticed that even mounting a freshly created XFS partition failed:
synpromika@server1 ~ % sudo mkfs.xfs -f -i size=2048 -m uuid="4568c300-ad83-4288-963e-badcd99bf54f" /dev/sdc1
meta-data=/dev/sdc1 isize=2048 agcount=4, agsize=6272 blks
= sectsz=4096 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=0
data = bsize=4096 blocks=25088, imaxpct=25
= sunit=128 swidth=64 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=1608, version=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
synpromika@server1 ~ % sudo mount /dev/sdc1 /mnt/ceph-recovery
SB stripe unit sanity check failed
Metadata corruption detected at 0x433840, xfs_sb block 0x0/0x1000
libxfs_writebufr: write verifer failed on xfs_sb bno 0x0/0x1000
cache_node_purge: refcount was 1, not zero (node=0x1d3c400)
SB stripe unit sanity check failed
Metadata corruption detected at 0x433840, xfs_sb block 0x18800/0x1000
libxfs_writebufr: write verifer failed on xfs_sb bno 0x18800/0x1000
SB stripe unit sanity check failed
Metadata corruption detected at 0x433840, xfs_sb block 0x0/0x1000
libxfs_writebufr: write verifer failed on xfs_sb bno 0x0/0x1000
SB stripe unit sanity check failed
Metadata corruption detected at 0x433840, xfs_sb block 0x24c00/0x1000
libxfs_writebufr: write verifer failed on xfs_sb bno 0x24c00/0x1000
SB stripe unit sanity check failed
Metadata corruption detected at 0x433840, xfs_sb block 0xc400/0x1000
libxfs_writebufr: write verifer failed on xfs_sb bno 0xc400/0x1000
releasing dirty buffer (bulk) to free list!releasing dirty buffer (bulk) to free list!releasing dirty buffer (bulk) to free list!releasing dirty buffer (bulk) to free list!found dirty buffer (bulk) on free list!bad magic number
bad magic number
Metadata corruption detected at 0x433840, xfs_sb block 0x0/0x1000
libxfs_writebufr: write verifer failed on xfs_sb bno 0x0/0x1000
releasing dirty buffer (bulk) to free list!mount: /mnt/ceph-recovery: wrong fs type, bad option, bad superblock on /dev/sdc1, missing codepage or helper program, or other error.
Ouch. This very much looked related to the actual issue we re seeing. So we tried to execute mkfs.xfs with a bunch of different sunit/swidth settings. Using -d sunit=512 -d swidth=512 at least worked then, so we decided to force its usage in the creation of our OSD XFS partition. This brought us a working XFS partition. Please note, sunit must not be larger than swidth (more on that later!).
Then we reconstructed how to restore all the metadata for the OSD (activate.monmap, active, block_uuid, bluefs, ceph_fsid, fsid, keyring, kv_backend, magic, mkfs_done, ready, require_osd_release, systemd, type, whoami). To identify the UUID, we can read the data from ceph --format json osd dump , like this for all our OSDs (Zsh syntax ftw!):
With all of this, we reconstructed the keyring, fsid, whoami, block + block_uuid files. All the other files inside the XFS metadata partition are identical on each OSD. So after placing and adjusting the corresponding metadata on the XFS partition for Ceph usage, we got a working OSD hurray! Since we had to fix yet another 32 OSDs, we decided to automate this XFS partitioning and metadata recovery procedure.
We had a network share available on /srv/backup for storing backups of existing partition data. On each server, we tested the procedure with one single OSD before iterating over the list of remaining failing OSDs. We started with a shell script on server1, then adjusted the script for server2 and server3. This is the script, as we executed it on the 3rd server.
Thanks to this, we managed to get the Ceph cluster up and running again. We didn t want to continue with the Ceph upgrade itself during the night though, as we wanted to know exactly what was going on and why the system behaved like that. Time for RCA!
Root Cause Analysis
So all but three OSDs on server2 failed, and the problem seems to be related to XFS. Therefore, our starting point for the RCA was, to identify what was different on server2, as compared to server1 + server3. My initial assumption was that this was related to some firmware issues with the involved controller (and as it turned out later, I was right!). The disks were attached as JBOD devices to a ServeRAID M5210 controller (with a stripe size of 512). Firmware state:
synpromika@server1 ~ % sudo storcli64 /c0 show all grep '^Firmware'
Firmware Package Build = 24.16.0-0092
Firmware Version = 4.660.00-8156
synpromika@server2 ~ % sudo storcli64 /c0 show all grep '^Firmware'
Firmware Package Build = 24.21.0-0112
Firmware Version = 4.680.00-8489
synpromika@server3 ~ % sudo storcli64 /c0 show all grep '^Firmware'
Firmware Package Build = 24.16.0-0092
Firmware Version = 4.660.00-8156
This looked very promising, as server2 indeed runs with a different firmware version on the controller. But how so? Well, the motherboard of server2 got replaced by a Lenovo/IBM technician in January 2020, as we had a failing memory slot during a memory upgrade. As part of this procedure, the Lenovo/IBM technician installed the latest firmware versions. According to our documentation, some OSDs were rebuilt (due to the filestore->bluestore migration) in March and April 2020. It turned out that precisely those OSDs were the ones that survived the upgrade. So the surviving drives were created with a different firmware version running on the involved controller. All the other OSDs were created with an older controller firmware. But what difference does this make?
Now let s check firmware changelogs. For the 24.21.0-0097 release we found this:
- Cannot create or mount xfs filesystem using xfsprogs 4.19.x kernel 4.20(SCGCQ02027889)
- xfs_info command run on an XFS file system created on a VD of strip size 1M shows sunit and swidth as 0(SCGCQ02056038)
Our XFS problem certainly was related to the controller s firmware. We also recalled that our monitoring system reported different sunit settings for the OSDs that were rebuilt in March and April. For example, OSD 21 was recreated and got different sunit settings:
WARN server2.example.org Mount options of /var/lib/ceph/osd/ceph-21 WARN - Missing: sunit=1024, Exceeding: sunit=512
We compared the new OSD 21 with an existing one (OSD 25 on server3):
synpromika@server2 ~ % systemctl show var-lib-ceph-osd-ceph\\x2d21.mount grep sunit
Options=rw,noatime,attr2,inode64,sunit=512,swidth=512,noquota
synpromika@server3 ~ % systemctl show var-lib-ceph-osd-ceph\\x2d25.mount grep sunit
Options=rw,noatime,attr2,inode64,sunit=1024,swidth=512,noquota
Thanks to our documentation, we could compare execution logs of their creation:
So back then, we even tried to track this down but couldn t make sense of it yet. But now this sounds very much like it is related to the problem we saw with this Ceph/XFS failure. We follow Occam s razor, assuming the simplest explanation is usually the right one, so let s check the disk properties and see what differs:
It doesn t make sense that the minimum I/O size (iomin, AKA BLKIOMIN) is bigger than the optimal I/O size (ioopt, AKA BLKIOOPT). This leads us to Bug 202127 cannot mount or create xfs on a 597T device, which matches our findings here. But why did this XFS partition work in the past and fails now with the newer kernel version?
The XFS behaviour change
Now given that we have backups of all the XFS partition, we wanted to track down, a) when this XFS behaviour was introduced, and b) whether, and if so how it would be possible to reuse the XFS partition without having to rebuild it from scratch (e.g. if you would have no working Ceph OSD or backups left).
Let s look at such a failing XFS partition with the Grml live system:
root@grml ~ # grml-version
grml64-full 2020.06 Release Codename Ausgehfuahangl [2020-06-24]
root@grml ~ # uname -a
Linux grml 5.6.0-2-amd64 #1 SMP Debian 5.6.14-2 (2020-06-09) x86_64 GNU/Linux
root@grml ~ # grml-hostname grml-2020-06
Setting hostname to grml-2020-06: done
root@grml ~ # exec zsh
root@grml-2020-06 ~ # dpkg -l xfsprogs util-linux
Desired=Unknown/Install/Remove/Purge/Hold
Status=Not/Inst/Conf-files/Unpacked/halF-conf/Half-inst/trig-aWait/Trig-pend
/ Err?=(none)/Reinst-required (Status,Err: uppercase=bad)
/ Name Version Architecture Description
+++-==============-============-============-=========================================
ii util-linux 2.35.2-4 amd64 miscellaneous system utilities
ii xfsprogs 5.6.0-1+b2 amd64 Utilities for managing the XFS filesystem
There it s failing, no matter which mount option we try:
Now let s try with an older kernel version (4.9.0), using old Grml 2017.05 release:
root@grml ~ # grml-version
grml64-small 2017.05 Release Codename Freedatensuppe [2017-05-31]
root@grml ~ # uname -a
Linux grml 4.9.0-1-grml-amd64 #1 SMP Debian 4.9.29-1+grml.1 (2017-05-24) x86_64 GNU/Linux
root@grml ~ # lsb_release -a
No LSB modules are available.
Distributor ID: Debian
Description: Debian GNU/Linux 9.0 (stretch)
Release: 9.0
Codename: stretch
root@grml ~ # grml-hostname grml-2017-05
Setting hostname to grml-2017-05: done
root@grml ~ # exec zsh
root@grml-2017-05 ~ #
root@grml-2017-05 ~ # xfs_info ./sdd1.dd
xfs_info: ./sdd1.dd is not a mounted XFS filesystem
1 root@grml-2017-05 ~ # xfs_repair ./sdd1.dd
Phase 1 - find and verify superblock...
bad primary superblock - bad stripe width in superblock !!!
attempting to find secondary superblock...
..............................................................................................Sorry, could not find valid secondary superblock
Exiting now.
1 root@grml-2017-05 ~ # mount ./sdd1.dd /mnt
root@grml-2017-05 ~ # mount -t xfs
/root/sdd1.dd on /mnt type xfs (rw,relatime,attr2,inode64,sunit=1024,swidth=512,noquota)
root@grml-2017-05 ~ # ls /mnt
activate.monmap active block block_uuid bluefs ceph_fsid fsid keyring kv_backend magic mkfs_done ready require_osd_release systemd type whoami
root@grml-2017-05 ~ # xfs_info /mnt
meta-data=/dev/loop1 isize=2048 agcount=4, agsize=6272 blks
= sectsz=4096 attr=2, projid32bit=1
= crc=1 finobt=1 spinodes=0 rmapbt=0
= reflink=0
data = bsize=4096 blocks=25088, imaxpct=25
= sunit=128 swidth=64 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=1608, version=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
Mounting there indeed works! Now, if we mount the filesystem with new and proper sunit/swidth settings using the older kernel, it should rewrite them on disk:
FTR: The sunit=512,swidth=512 from the xfs mount option is identical to xfs_info s output sunit=64,swidth=64 (because mount.xfs s sunit value is given in 512-byte block units, see man 5 xfs, and the xfs_info output reported here is in blocks with a block size (bsize) of 4096, so sunit = 512*512 := 64*4096 ).
mkfs uses minimum and optimal sizes for stripe unit and stripe width; you can check this e.g. via (note that server2 with fixed firmware version reports proper values, whereas server3 with broken controller firmware reports non-sense):
This is the underlying reason why the initially created XFS partitions were created with incorrect sunit/swidth settings. The broken firmware of server1 and server3 was the cause of the incorrect settings they were ignored by old(er) xfs/kernel versions, but treated as an error by new ones.
Make sure to also read the XFS FAQ regarding How to calculate the correct sunit,swidth values for optimal performance . We also stumbled upon two interesting reads in RedHat s knowledge base: 5075561 + 2150101 (requires an active subscription, though) and #1835947.
Am I affected? How to work around it?
To check whether your XFS mount points are affected by this issue, the following command line should be useful:
If you run into the above situation, the only known solution to get your original XFS partition working again, is to boot into an older kernel version again (4.17 or older), mount the XFS partition with correct sunit/swidth settings and then boot back into your new system (kernel version wise).
Lessons learned
document everything and ensure to have all relevant information available (including actual times of changes, used kernel/package/firmware/ versions. The thorough documentation was our most significant asset in this case, because we had all the data and information we needed during the emergency handling as well as for the post mortem/RCA)
if something changes unexpectedly, dig deeper
know who to ask, a network of experts pays off
including timestamps in your shell makes reconstruction easier (the more people and documentation involved, the harder it gets to wade through it)
keep an eye on changelogs/release notes
apply regular updates and don t forget invisible layers (e.g. BIOS, controller/disk firmware, IPMI/OOB (ILO/RAC/IMM/ ) firmware)
apply regular reboots, to avoid a possible delta becoming bigger (which makes debugging harder)
Thanks: Darshaka Pathirana, Chris Hofstaedtler and Michael Hanscho.
Looking for help with your IT infrastructure? Let us know!
In 14 years since starting this blog, I changed the software several times,
with each iteration simplifying requirements and setup.
Wordpress
In 2007, I started blogging. Back then I used a self-hosted
Wordpress instance, running on my server. I was never really comfortable
with the technology stack involved: a programming language I didn't
speak, a DB I had little experience with, a relatively heavy setup
and of course, the occasional security issues related to that setup. All that
just to have a somewhat dynamic website with pingbacks and
comments generated by your visitors... totally worth it and exciting
times! You wrote something to the "lazyweb" department and people would
actually comment with useful advice!
Then came the spammers. First, it was just a little, and you could easily
fight it off with the askimet plugin. Over the years, however the
spam-to-useful-comments-ratio shifted to ridiculous levels and the comment
section itself became a burden. Hosting the comments on a separate platform
like disqus was not an option for me, so I finally turned the comments
off.
Without the need for a comment section, the whole idea of storing mostly
textual content in a DB just to have it served as a website, suddenly seemed
like overkill and an unnecessary security risk. So I started looking for
alternatives.
I wanted to maintain my content as plain text files. Text files are cool
because they are future proof, portable and can be managed in git.
Consequently, I was searching for a static site generator.
Pelican
Around 2016 I finally migrated away from Wordpress to Pelican. Pelican met
all my requirements. I could store my content as plain Markdown files in a git
repository. Pelican is written in Python, a language with which I'm very
comfortable with. Pelican deals with blog posts and "pages" (i.e. non blog
articles) and most importantly: Pelican just generates static HTML. So all
that's required on the server side is a simple web server.
Conveniently, it also comes with an importer that allowed me to export the
content of my old Wordpress instance straight into Markdown files.
Migrating to Pelican was a huge relieve: I finally had a all my content as
plain text in a git repository, my server was a lot more secure without the
Wordpress instance running and removing MySQL freed up a lot of resources on
that machine.
blag
Fast forward to 2021. While I was quite happy with Pelican, it still had too
many features I don't need. My blogging experience can be stripped down to a
bunch of Markdown files that serve either as articles or pages, some static
files, some templating for a decent design and an Atom feed. Particularly, I
do not need pages/articles in multiple languages, a plugin system, support for
multiple authors and tons of settings.
So I did what every self-respecting nerd would do: I wrote my own site
generator. Not to write something better than Pelican, but rather something
lesser. Something that does less while still being functionally adequate.
I called the result "blag", named after the blag of the webcomic
xkcd. blag is a blog-aware, static site generator written in
Python. It supports the basic features you'd expect from a blog, like an
archive, tags and an Atom feed. It converts Markdown (with fenced code
blocks) and supports Jinja2 templating.
With this setup I'm quite happy for now. Maybe sometime there will be a
simpler RSS/Atom-successor that does not require site-specific metadata
(i.e. only stuff that can be generated from the articles themselves), so I
could get rid of blag's only required configuration.
I won't reveal precisely how many books I read in 2020, but it was definitely an improvement on 74 in 2019, 53 in 2018 and 50 in 2017. But not only did I read more in a quantitative sense, the quality seemed higher as well. There were certainly fewer disappointments: given its cultural resonance, I was nonplussed by Nick Hornby's Fever Pitch and whilst Ian Fleming's The Man with the Golden Gun was a little thin (again, given the obvious influence of the Bond franchise) the booked lacked 'thinness' in a way that made it interesting to critique. The weakest novel I read this year was probably J. M. Berger's Optimal, but even this hybrid of Ready Player One late-period Black Mirror wasn't that cringeworthy, all things considered. Alas, graphic novels continue to not quite be my thing, I'm afraid.
I perhaps experienced more disappointments in the non-fiction section. Paul Bloom's Against Empathy was frustrating, particularly in that it expended unnecessary energy battling its misleading title and accepted terminology, and it could so easily have been an 20-minute video essay instead). (Elsewhere in the social sciences, David and Goliath will likely be the last Malcolm Gladwell book I voluntarily read.) After so many positive citations, I was also more than a little underwhelmed by Shoshana Zuboff's The Age of Surveillance Capitalism, and after Ryan Holiday's manyengagingreboots of Stoic philosophy, his Conspiracy (on Peter Thiel and Hulk Hogan taking on Gawker) was slightly wide of the mark for me.
Anyway, here follows a selection of my favourites from 2020, in no particular order:
Fiction
Wolf Hall & Bring Up the Bodies & The Mirror and the LightHilary Mantel
During the early weeks of 2020, I re-read the first two parts of Hilary Mantel's Thomas Cromwell trilogy in time for the March release of The Mirror and the Light. I had actually spent the last few years eagerly following any news of the final instalment, feigning outrage whenever Mantel appeared to be spending time on other projects.
Wolf Hall turned out to be an even better book than I remembered, and when The Mirror and the Light finally landed at midnight on 5th March, I began in earnest the next morning. Note that date carefully; this was early 2020, and the book swiftly became something of a heavy-handed allegory about the world at the time. That is to say and without claiming that I am Monsieur Cromuel in any meaningful sense it was an uneasy experience to be reading about a man whose confident grasp on his world, friends and life was slipping beyond his control, and at least in Cromwell's case, was heading inexorably towards its denouement.
The final instalment in Mantel's trilogy is not perfect, and despite my love of her writing I would concur with the judges who decided against awarding her a third Booker Prize. For instance, there is something of the longueur that readers dislike in the second novel, although this might not be entirely Mantel's fault after all, the rise of the "ugly" Anne of Cleves and laborious trade negotiations for an uninspiring mineral (this is no Herbertian 'spice') will never match the court intrigues of Anne Boleyn, Jane Seymour and that man for all seasons, Thomas More. Still, I am already looking forward to returning to the verbal sparring between King Henry and Cromwell when I read the entire trilogy once again, tentatively planned for 2022.
The Fault in Our StarsJohn Green
I came across John Green's The Fault in Our Stars via a fantastic video by Lindsay Ellis discussing Roland Barthes famous 1967 essay on authorial intent. However, I might have eventually come across The Fault in Our Stars regardless, not because of Green's status as an internet celebrity of sorts but because I'm a complete sucker for this kind of emotionally-manipulative bildungsroman, likely due to reading Philip Pullman's His Dark Materials a few too many times in my teens.
Although its title is taken from Shakespeare's Julius Caesar, The Fault in Our Stars is actually more Romeo & Juliet. Hazel, a 16-year-old cancer patient falls in love with Gus, an equally ill teen from her cancer support group. Hazel and Gus share the same acerbic (and distinctly unteenage) wit and a love of books, centred around Hazel's obsession of An Imperial Affliction, a novel by the meta-fictional author Peter Van Houten. Through a kind of American version of Jim'll Fix It, Gus and Hazel go and visit Van Houten in Amsterdam.
I'm afraid it's even cheesier than I'm describing it. Yet just as there is a time and a place for Michelin stars and Haribo Starmix, there's surely a place for this kind of well-constructed but altogether maudlin literature. One test for emotionally manipulative works like this is how well it can mask its internal contradictions while Green's story focuses on the universalities of love, fate and the shortness of life (as do almost all of his works, it seems), The Fault in Our Stars manages to hide, for example, that this is an exceedingly favourable treatment of terminal illness that is only possible for the better off. The 2014 film adaptation does somewhat worse in peddling this fantasy (and has a much weaker treatment of the relationship between the teens' parents too, an underappreciated subtlety of the book).
The novel, however, is pretty slick stuff, and it is difficult to fault it for what it is. For some comparison, I later read Green's Looking for Alaska and Paper Towns which, as I mention, tug at many of the same strings, but they don't come together nearly as well as The Fault in Our Stars. James Joyce claimed that "sentimentality is unearned emotion", and in this respect, The Fault in Our Stars really does earn it.
The PlagueAlbert Camus
P. D. James' The Children of Men, George Orwell's Nineteen Eighty-Four, Arthur Koestler's Darkness at Noon ... dystopian fiction was already a theme of my reading in 2020, so given world events it was an inevitability that I would end up with Camus's novel about a plague that swept through the Algerian city of Oran.
Is The Plague an allegory about the Nazi occupation of France during World War Two? Where are all the female characters? Where are the Arab ones? Since its original publication in 1947, there's been so much written about The Plague that it's hard to say anything new today. Nevertheless, I was taken aback by how well it captured so much of the nuance of 2020. Whilst we were saying just how 'unprecedented' these times were, it was eerie how a novel written in the 1940s could accurately how many of us were feeling well over seventy years on later: the attitudes of the people; the confident declarations from the institutions; the misaligned conversations that led to accidental misunderstandings. The disconnected lovers.
The only thing that perhaps did not work for me in The Plague was the 'character' of the church. Although I could appreciate most of the allusion and metaphor, it was difficult for me to relate to the significance of Father Paneloux, particularly regarding his change of view on the doctrinal implications of the virus, and spoiler alert that he finally died of a "doubtful case" of the disease, beyond the idea that Paneloux's beliefs are in themselves "doubtful". Answers on a postcard, perhaps.
The Plague even seemed to predict how we, at least speaking of the UK, would react when the waves of the virus waxed and waned as well:
The disease stiffened and carried off three or four patients who were expected to recover. These were the unfortunates of the plague, those whom it killed when hope was high
It somehow captured the nostalgic yearning for high-definition videos of cities and public transport; one character even visits the completely deserted railway station in Oman simply to read the timetables on the wall.
Tinker, Tailor, Soldier, SpyJohn le Carr
There's absolutely none of the Mad Men glamour of James Bond in John le Carr 's icy world of Cold War spies:
Small, podgy, and at best middle-aged, Smiley was by appearance one of London's meek who do not inherit the earth. His legs were short, his gait anything but agile, his dress costly, ill-fitting, and extremely wet.
Almost a direct rebuttal to Ian Fleming's 007, Tinker, Tailor has broken-down cars, bad clothes, women with their own internal and external lives (!), pathetically primitive gadgets, and (contra Mad Men) hangovers that significantly longer than ten minutes. In fact, the main aspect that the mostly excellent 2011 film adaption doesn't really capture is the smoggy and run-down nature of 1970s London this is not your proto-Cool Britannia of Austin Powers or GTA:1969, the city is truly 'gritty' in the sense there is a thin film of dirt and grime on every surface imaginable.
Another angle that the film cannot capture well is just how purposefully the novel does not mention the United States. Despite the US obviously being the dominant power, the British vacillate between pretending it doesn't exist or implying its irrelevance to the matter at hand. This is no mistake on Le Carr 's part, as careful readers are rewarded by finding this denial of US hegemony in metaphor throughout --pace Ian Fleming, there is no obvious Felix Leiter to loudly throw money at the problem or a Sheriff Pepper to serve as cartoon racist for the Brits to feel superior about. By contrast, I recall that a clever allusion to "dusty teabags" is subtly mirrored a few paragraphs later with a reference to the installation of a coffee machine in the office, likely symbolic of the omnipresent and unavoidable influence of America. (The officer class convince themselves that coffee is a European import.) Indeed, Le Carr communicates a feeling of being surrounded on all sides by the peeling wallpaper of Empire.
Oftentimes, the writing style matches the graceless and inelegance of the world it depicts. The sentences are dense and you find your brain performing a fair amount of mid-flight sentence reconstruction, reparsing clauses, commas and conjunctions to interpret Le Carr 's intended meaning. In fact, in his eulogy-cum-analysis of Le Carr 's writing style, William Boyd, himself a ventrioquilist of Ian Fleming, named this intentional technique 'staccato'. Like the musical term, I suspect the effect of this literary staccato is as much about the impact it makes on a sentence as the imperceptible space it generates after it.
Lastly, the large cast in this sprawling novel is completely believable, all the way from the Russian spymaster Karla to minor schoolboy Roach the latter possibly a stand-in for Le Carr himself. I got through the 500-odd pages in just a few days, somehow managing to hold the almost-absurdly complicated plot in my head. This is one of those classic books of the genre that made me wonder why I had not got around to it before.
The Nickel BoysColson Whitehead
According to the judges who awarded it the Pulitzer Prize for Fiction, The Nickel Boys is "a devastating exploration of abuse at a reform school in Jim Crow-era Florida" that serves as a "powerful tale of human perseverance, dignity and redemption". But whilst there is plenty of this perseverance and dignity on display, I found little redemption in this deeply cynical novel.
It could almost be read as a follow-up book to Whitehead's popular The Underground Railroad, which itself won the Pulitzer Prize in 2017. Indeed, each book focuses on a young protagonist who might be euphemistically referred to as 'downtrodden'. But The Nickel Boys is not only far darker in tone, it feels much closer and more connected to us today. Perhaps this is unsurprising, given that it is based on the story of the Dozier School in northern Florida which operated for over a century before its long history of institutional abuse and racism was exposed a 2012 investigation. Nevertheless, if you liked the social commentary in The Underground Railroad, then there is much more of that in The Nickel Boys:
Perhaps his life might have veered elsewhere if the US government had opened the country to colored advancement like they opened the army. But it was one thing to allow someone to kill for you and another to let him live next door.
Sardonic aper us of this kind are pretty relentless throughout the book, but it never tips its hand too far into on nihilism, especially when some of the visual metaphors are often first-rate: "An American flag sighed on a pole" is one I can easily recall from memory. In general though, The Nickel Boys is not only more world-weary in tenor than his previous novel, the United States it describes seems almost too beaten down to have the energy conjure up the Swiftian magical realism that prevented The Underground Railroad from being overly lachrymose. Indeed, even we Whitehead transports us a present-day New York City, we can't indulge in another kind of fantasy, the one where America has solved its problems:
The Daily News review described the [Manhattan restaurant] as nouveau Southern, "down-home plates with a twist." What was the twist that it was soul food made by white people?
It might be overly reductionist to connect Whitehead's tonal downshift with the racial justice movements of the past few years, but whatever the reason, we've ended up with a hard-hitting, crushing and frankly excellent book.
True Grit & No Country for Old MenCharles Portis & Cormac McCarthy
It's one of the most tedious cliches to claim the book is better than the film, but these two books are of such high quality that even the Coen Brothers at their best cannot transcend them. I'm grouping these books together here though, not because their respective adaptations will exemplify some of the best cinema of the 21st century, but because of their superb treatment of language.
Take the use of dialogue. Cormac McCarthy famously does not use any punctuation "I believe in periods, in capitals, in the occasional comma, and that's it" but the conversations in No Country for Old Men together feel familiar and commonplace, despite being relayed through this unconventional technique. In lesser hands, McCarthy's written-out Texan drawl would be the novelistic equivalent of white rap or Jar Jar Binks, but not only is the effect entirely gripping, it helps you to believe you are physically present in the many intimate and domestic conversations that hold this book together. Perhaps the cinematic familiarity helps, as you can almost hear Tommy Lee Jones' voice as Sheriff Bell from the opening page to the last.
Charles Portis' True Grit excels in its dialogue too, but in this book it is not so much in how it flows (although that is delightful in its own way) but in how forthright and sardonic Maddie Ross is:
"Earlier tonight I gave some thought to stealing a kiss from you, though you are very young, and sick and unattractive to boot, but now I am of a mind to give you five or six good licks with my belt."
"One would be as unpleasant as the other."
Perhaps this should be unsurprising. Maddie, a fourteen-year-old girl from Yell County, Arkansas, can barely fire her father's heavy pistol, so she can only has words to wield as her weapon. Anyway, it's not just me who treasures this book. In her encomium that presages most modern editions, Donna Tartt of The Secret History fame traces the novels origins through Huckleberry Finn, praising its elegance and economy: "The plot of True Grit is uncomplicated and as pure in its way as one of the Canterbury Tales". I've read any Chaucer, but I am inclined to agree.
Tartt also recalls that True Grit vanished almost entirely from the public eye after the release of John Wayne's flimsy cinematic vehicle in 1969 this earlier film was, Tartt believes, "good enough, but doesn't do the book justice". As it happens, reading a book with its big screen adaptation as a chaser has been a minor theme of my 2020, including P. D. James' The Children of Men, Kazuo Ishiguro's Never Let Me Go, Patricia Highsmith's Strangers on a Train, James Ellroy's The Black Dahlia, John Green's The Fault in Our Stars, John le Carr 's Tinker, Tailor Soldier, Spy and even a staged production of Charles Dicken's A Christmas Carol streamed from The Old Vic. For an autodidact with no academic background in literature or cinema, I've been finding this an effective and enjoyable means of getting closer to these fine books and films it is precisely where they deviate (or perhaps where they are deficient) that offers a means by which one can see how they were constructed. I've also found that adaptations can also tell you a lot about the culture in which they were made: take the 'straightwashing' in the film version of Strangers on a Train (1951) compared to the original novel, for example. It is certainly true that adaptions rarely (as Tartt put it) "do the book justice", but she might be also right to alight on a legal metaphor, for as the saying goes, to judge a movie in comparison to the book is to do both a disservice.
The Glass HotelEmily St. John Mandel
In The Glass Hotel, Mandel somehow pulls off the impossible; writing a loose roman- -clef on Bernie Madoff, a Ponzi scheme and the ephemeral nature of finance capital that is tranquil and shimmeringly beautiful. Indeed, don't get the wrong idea about the subject matter; this is no over over-caffeinated The Big Short, as The Glass Hotel is less about a Madoff or coked-up financebros but the fragile unreality of the late 2010s, a time which was, as we indeed discovered in 2020, one event away from almost shattering completely.
Mandel's prose has that translucent, phantom quality to it where the chapters slip through your fingers when you try to grasp at them, and the plot is like a ghost ship that that slips silently, like the Mary Celeste, onto the Canadian water next to which the eponymous 'Glass Hotel' resides. Indeed, not unlike The Overlook Hotel, the novel so overflows with symbolism so that even the title needs to evoke the idea of impermanence permanently living in a hotel might serve as a house, but it won't provide a home. It's risky to generalise about such things post-2016, but the whole story sits in that the infinitesimally small distance between perception and reality, a self-constructed culture that is not so much 'post truth' but between them.
There's something to consider in almost every character too. Take the stand-in for Bernie Madoff: no caricature of Wall Street out of a 1920s political cartoon or Brechtian satire, Jonathan Alkaitis has none of the oleaginous sleaze of a Dominic Strauss-Kahn, the cold sociopathy of a Marcus Halberstam nor the well-exercised sinuses of, say, Jordan Belford. Alkaitis is dare I say it? eminently likeable, and the book is all the better for it. Even the C-level characters have something to say: Enrico, trivially escaping from the regulators (who are pathetically late to the fraud without Mandel ever telling us explicitly), is daydreaming about the girlfriend he abandoned in New York: "He wished he'd realised he loved her before he left". What was in his previous life that prevented him from doing so? Perhaps he was never in love at all, or is love itself just as transient as the imaginary money in all those bank accounts? Maybe he fell in love just as he crossed safely into Mexico? When, precisely, do we fall in love anyway?
I went on to read Mandel's Last Night in Montreal, an early work where you can feel her reaching for that other-worldly quality that she so masterfully achieves in The Glass Hotel. Her f ted Station Eleven is on my must-read list for 2021. "What is truth?" asked Pontius Pilate. Not even Mandel cannot give us the answer, but this will certainly do for now.
Running the LightSam Tallent
Although it trades in all of the clich s and stereotypes of the stand-up comedian (the triumvirate of drink, drugs and divorce), Sam Tallent's debut novel depicts an extremely convincing fictional account of a touring road comic.
The comedian Doug Stanhope (who himself released a fairly decent No Encore for the Donkey memoir in 2020) hyped Sam's book relentlessly on his podcast during lockdown... and justifiably so. I ripped through Running the Light in a few short hours, the only disappointment being that I can't seem to find videos online of Sam that come anywhere close to match up to his writing style. If you liked the rollercoaster energy of Paul Beatty's The Sellout, the cynicism of George Carlin and the car-crash invertibility of final season Breaking Bad, check this great book out.
Non-fiction
Inside StoryMartin Amis
This was my first introduction to Martin Amis's work after hearing that his "novelised autobiography" contained a fair amount about Christopher Hitchens, an author with whom I had a one of those rather clich d parasocial relationship with in the early days of YouTube. (Hey, it couldhavebeenmuchworse.) Amis calls his book a "novelised autobiography", and just as much has been made of its quasi-fictional nature as the many diversions into didactic writing advice that betwixt each chapter: "Not content with being a novel, this book also wants to tell you how to write novels", complained Tim Adams in The Guardian.
I suspect that reviewers who grew up with Martin since his debut book in 1973 rolled their eyes at yet another demonstration of his manifest cleverness, but as my first exposure to Amis's gift of observation, I confess that I was thought it was actually kinda clever. Try, for example, "it remains a maddening truth that both sexual success and sexual failure are steeply self-perpetuating" or "a hospital gym is a contradiction like a young Conservative", etc. Then again, perhaps I was experiencing a form of nostalgia for a pre-Gamergate YouTube, when everything in the world was a lot simpler... or at least things could be solved by articulate gentlemen who honed their art of rhetoric at the Oxford Union.
I went on to read Martin's first novel, The Rachel Papers (is it 'arrogance' if you are, indeed, that confident?), as well as his 1997 Night Train. I plan to read more of him in the future.
The Collected Essays, Journalism and Letters: Volume 1 & Volume 2 & Volume 3 & Volume 4George Orwell
These deceptively bulky four volumes contain all of George Orwell's essays, reviews and correspondence, from his teenage letters sent to local newspapers to notes to his literary executor on his deathbed in 1950. Reading this was part of a larger, multi-year project of mine to cover the entirety of his output.
By including this here, however, I'm not recommending that you read everything that came out of Orwell's typewriter. The letters to friends and publishers will only be interesting to biographers or hardcore fans (although I would recommend Dorian Lynskey's The Ministry of Truth: A Biography of George Orwell's 1984 first). Furthermore, many of his book reviews will be of little interest today. Still, some insights can be gleaned; if there is any inconsistency in this huge corpus is that his best work is almost 'too' good and too impactful, making his merely-average writing appear like hackwork. There are some gems that don't make the usual essay collections too, and some of Orwell's most astute social commentary came out of series of articles he wrote for the left-leaning newspaper Tribune, related in many ways to the US Jacobin. You can also see some of his most famous ideas start to take shape years if not decades before they appear in his novels in these prototype blog posts.
I also read Dennis Glover's novelised account of the writing of Nineteen-Eighty Four called The Last Man in Europe, and I plan to re-read some of Orwell's earlier novels during 2021 too, including A Clergyman's Daughter and his 'antebellum' Coming Up for Air that he wrote just before the Second World War; his most under-rated novel in my estimation. As it happens, and with the exception of the US and Spain, copyright in the works published in his lifetime ends on 1st January 2021. Make of that what you will.
Capitalist Realism & Chavs: The Demonisation of the Working ClassMark Fisher & Owen Jones
These two books are not natural companions to one another and there is likely much that Jones and Fisher would vehemently disagree on, but I am pairing these books together here because they represent the best of the 'political' books I read in 2020.
Mark Fisher was a dedicated leftist whose first book, Capitalist Realism, marked an important contribution to political philosophy in the UK. However, since his suicide in early 2017, the currency of his writing has markedly risen, and Fisher is now frequently referenced due to his belief that the prevalence of mental health conditions in modern life is a side-effect of various material conditions, rather than a natural or unalterable fact "like weather". (Of course, our 'weather' is being increasingly determined by a combination of politics, economics and petrochemistry than pure randomness.) Still, Fisher wrote on all manner of topics, from the 2012 London Olympics and "weird and eerie" electronic music that yearns for a lost future that will never arrive, possibly prefiguring or influencing the Fallout video game series.
Saying that, I suspect Fisher will resonate better with a UK audience more than one across the Atlantic, not necessarily because he was minded to write about the parochial politics and culture of Britain, but because his writing often carries some exasperation at the suppression of class in favour of identity-oriented politics, a viewpoint not entirely prevalent in the United States outside of, say, Tour F. Reed or the late Michael Brooks. (Indeed, Fisher is likely best known in the US as the author of his controversial 2013 essay, Exiting the Vampire Castle, but that does not figure greatly in this book). Regardless, Capitalist Realism is an insightful, damning and deeply unoptimistic book, best enjoyed in the warm sunshine I found it an ironic compliment that I had quoted so many paragraphs that my Kindle's copy protection routines prevented me from clipping any further.
Owen Jones needs no introduction to anyone who regularly reads a British newspaper, especially since 2015 where he unofficially served as a proxy and punching bag for expressing frustrations with the then-Labour leader, Jeremy Corbyn. However, as the subtitle of Jones' 2012 book suggests, Chavs attempts to reveal the "demonisation of the working class" in post-financial crisis Britain. Indeed, the timing of the book is central to Jones' analysis, specifically that the stereotype of the "chav" is used by government and the media as a convenient figleaf to avoid meaningful engagement with economic and social problems on an austerity ridden island. (I'm not quite sure what the US equivalent to 'chav' might be. Perhaps Florida Man without the implications of mental health.)
Anyway, Jones certainly has a point. From Vicky Pollard to the attacks on Jade Goody, there is an ignorance and prejudice at the heart of the 'chav' backlash, and that would be bad enough even if it was not being co-opted or criminalised for ideological ends.
Elsewhere in political science, I also caught Michael Brooks' Against the Web and David Graeber's Bullshit Jobs, although they are not quite methodical enough to recommend here. However, Graeber's award-winning Debt: The First 5000 Years will be read in 2021. Matt Taibbi's Hate Inc: Why Today's Media Makes Us Despise One Another is worth a brief mention here though, but its sprawling nature felt very much like I was reading a set of Substack articles loosely edited together. And, indeed, I was.
The Golden Thread: The Story of WritingEwan Clayton
A recommendation from a dear friend, Ewan Clayton's The Golden Thread is a journey through the long history of the writing from the Dawn of Man to present day. Whether you are a linguist, a graphic designer, a visual artist, a typographer, an archaeologist or 'just' a reader, there is probably something in here for you. I was already dipping my quill into calligraphy this year so I suspect I would have liked this book in any case, but highlights would definitely include the changing role of writing due to the influence of textual forms in the workplace as well as digression on ergonomic desks employed by monks and scribes in the Middle Ages.
A lot of books by otherwise-sensible authors overstretch themselves when they write about computers or other technology from the Information Age, at best resulting in bizarre non-sequiturs and dangerously Panglossian viewpoints at worst. But Clayton surprised me by writing extremely cogently and accurate on the role of text in this new and unpredictable era. After finishing it I realised why for a number of years, Clayton was a consultant for the legendary Xerox PARC where he worked in a group focusing on documents and contemporary communications whilst his colleagues were busy inventing the graphical user interface, laser printing, text editors and the computer mouse.
We're accustomed to worrying about AI systems being built that will either "go rogue" and attack us, or succeed us in a bizarre evolution of, um, evolution what we didn't reckon on is the sheer inscrutability of these manufactured minds. And minds is not a misnomer. How else should we think about the neural network Google has built so its translator can model the interrelation of all words in all languages, in a kind of three-dimensional "semantic space"?
New Dark Age also turns its attention to the weird, algorithmically-derived products offered for sale on Amazon as well as the disturbing and abusive videos that are automatically uploaded by bots to YouTube. It should, by rights, be a mess of disparate ideas and concerns, but Bridle has a flair for introducing topics which reveals he comes to computer science from another discipline altogether; indeed, on a four-part series he made for Radio 4, he's primarily referred to as "an artist".
Whilst New Dark Age has rather abstract section topics, Adam Greenfield's Radical Technologies is a rather different book altogether. Each chapter dissects one of the so-called 'radical' technologies that condition the choices available to us, asking how do they work, what challenges do they present to us and who ultimately benefits from their adoption. Greenfield takes his scalpel to smartphones, machine learning, cryptocurrencies, artificial intelligence, etc., and I don't think it would be unfair to say that starts and ends with a cynical point of view. He is no reactionary Luddite, though, and this is both informed and extremely well-explained, and it also lacks the lazy, affected and Private Eye-like cynicism of, say, Attack of the 50 Foot Blockchain.
The books aren't a natural pair, for Bridle's writing contains quite a bit of air in places, ironically mimics the very 'clouds' he inveighs against. Greenfield's book, by contrast, as little air and much lower pH value. Still, it was more than refreshing to read two technology books that do not limit themselves to platitudinal booleans, be those dangerously naive (e.g. Kevin Kelly's The Inevitable) or relentlessly nihilistic (Shoshana Zuboff's The Age of Surveillance Capitalism). Sure, they are both anti-technology screeds, but they tend to make arguments about systems of power rather than specific companies and avoid being too anti-'Big Tech' through a narrower, Silicon Valley obsessed lens for that (dipping into some other 2020 reading of mine) I might suggest Wendy Liu's Abolish Silicon Valley or Scott Galloway's The Four.
Still, both books are superlatively written. In fact, Adam Greenfield has some of the best non-fiction writing around, both in terms of how he can explain complicated concepts (particularly the smart contract mechanism of the Ethereum cryptocurrency) as well as in the extremely finely-crafted sentences I often felt that the writing style almost had no need to be that poetic, and I particularly enjoyed his fictional scenarios at the end of the book.
The Algebra of Happiness & Indistractable: How to Control Your Attention and Choose Your LifeScott Galloway & Nir Eyal
A cocktail of insight, informality and abrasiveness makes NYU Professor Scott Galloway uncannily appealing to guys around my age. Although Galloway definitely has his own wisdom and experience, similar to Joe Rogan I suspect that a crucial part of Galloway's appeal is that you feel you are learning right alongside him. Thankfully, 'Prof G' is far less err problematic than Rogan (Galloway is more of a well-meaning, spirited centrist), although he, too, has some pretty awful takes at time. This is a shame, because removed from the whirlwind of social media he can be really quite considered, such as in this long-form interview with Stephanie Ruhle.
In fact, it is this kind of sentiment that he captured in his 2019 Algebra of Happiness. When I look over my highlighted sections, it's clear that it's rather schmaltzy out of context ("Things you hate become just inconveniences in the presence of people you love..."), but his one-two punch of cynicism and saccharine ("Ask somebody who purchased a home in 2007 if their 'American Dream' came true...") is weirdly effective, especially when he uses his own family experiences as part of his story:
A better proxy for your life isn't your first home, but your last. Where you draw your last breath is more meaningful, as it's a reflection of your success and, more important, the number of people who care about your well-being. Your first house signals the meaningful your future and possibility. Your last home signals the profound the people who love you. Where you die, and who is around you at the end, is a strong signal of your success or failure in life.
Nir Eyal's Indistractable, however, is a totally different kind of 'self-help' book. The important background story is that Eyal was the author of the widely-read Hooked which turned into a secular Bible of so-called 'addictive design'. (If you've ever been cornered by a techbro wielding a Wikipedia-thin knowledge of B. F. Skinner's behaviourist psychology and how it can get you to click 'Like' more often, it ultimately came from Hooked.) However, Eyal's latest effort is actually an extended mea culpa for his previous sin and he offers both high and low-level palliative advice on how to avoid falling for the tricks he so studiously espoused before. I suppose we should be thankful to capitalism for selling both cause and cure.
Speaking of markets, there appears to be a growing appetite for books in this 'anti-distraction' category, and whilst I cannot claim to have done an exhausting study of this nascent field, Indistractable argues its points well without relying on accurate-but-dry "studies show..." or, worse, Gladwellian gotchas. My main criticism, however, would be that Eyal doesn't acknowledge the limits of a self-help approach to this problem; it seems that many of the issues he outlines are an inescapable part of the alienation in modern Western society, and the only way one can really avoid distraction is to move up the income ladder or move out to a 500-acre ranch.



 The
The 














 After a
After a  (Yes, this got in the way of working out what was going on with
(Yes, this got in the way of working out what was going on with  This isn t completely satisfying as we never quite got to the bottom of the
leak itself, and it s entirely possible that we ve only papered over it
using
This isn t completely satisfying as we never quite got to the bottom of the
leak itself, and it s entirely possible that we ve only papered over it
using  A new minor release of our
A new minor release of our 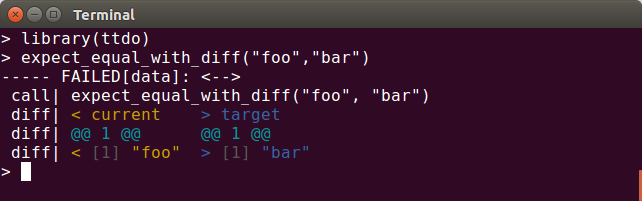 This release is mostly procedural to accomodate changes in
This release is mostly procedural to accomodate changes in  Prerequisites
You will need the following prerequisites :
Prerequisites
You will need the following prerequisites :
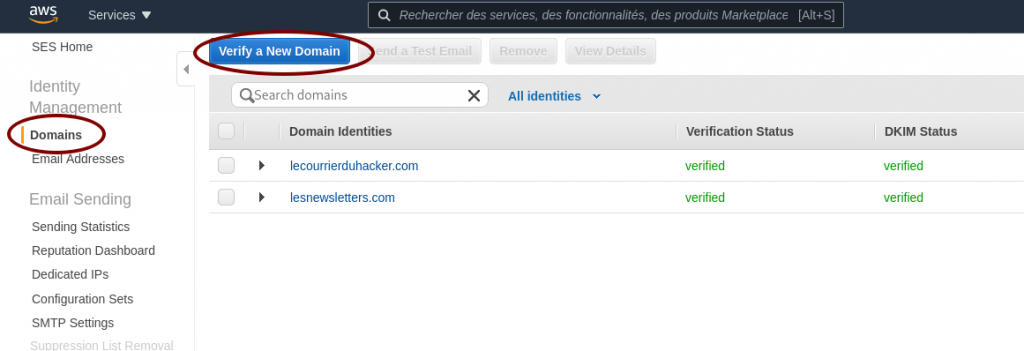 Ask AWS SES to verify a domain
Ask AWS SES to verify a domain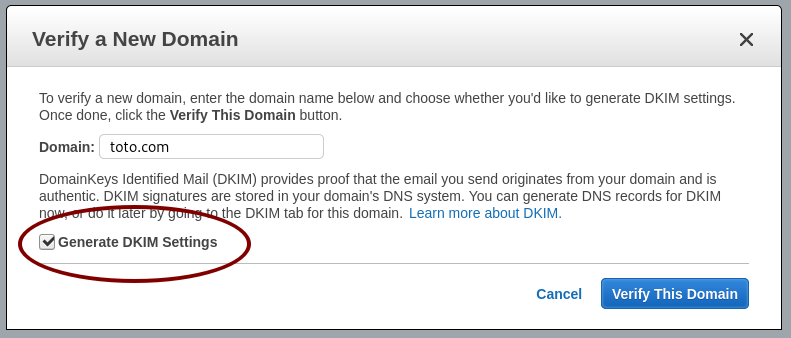 Generate the DKIM settings
Generate the DKIM settings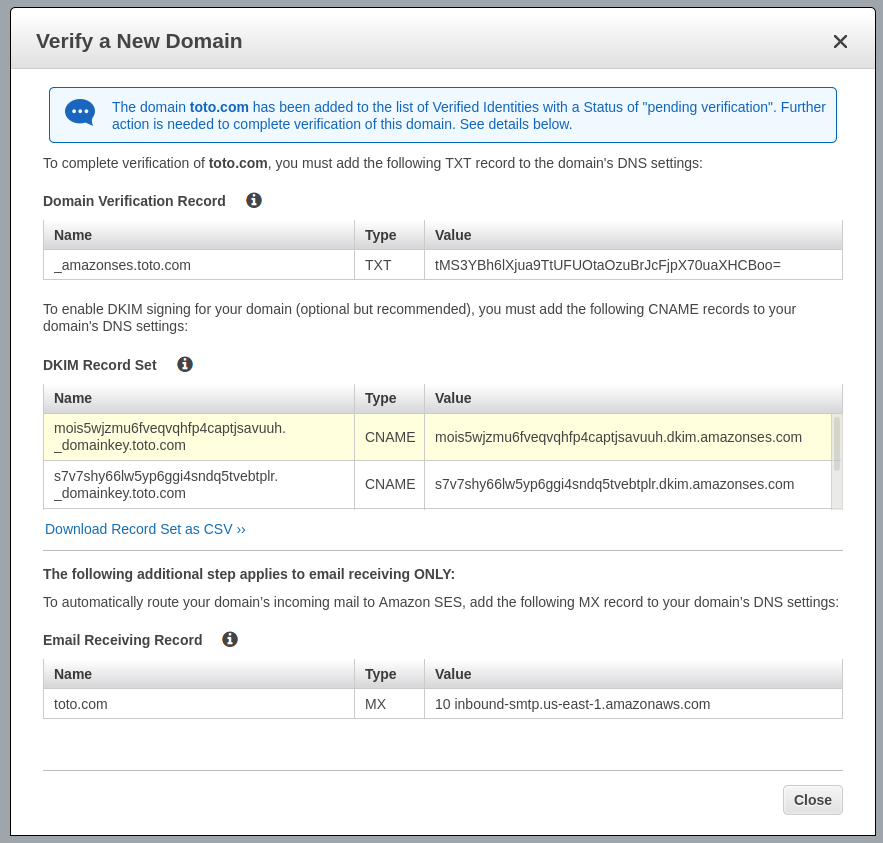
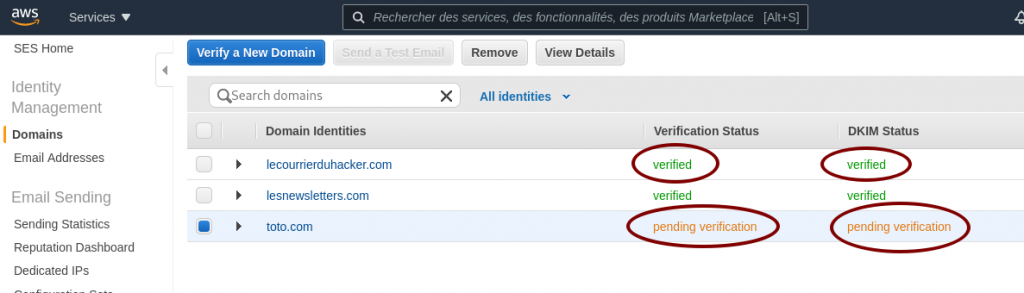 AWS SES pending verification
AWS SES pending verification AWS SES SMTP settings and credentials
AWS SES SMTP settings and credentials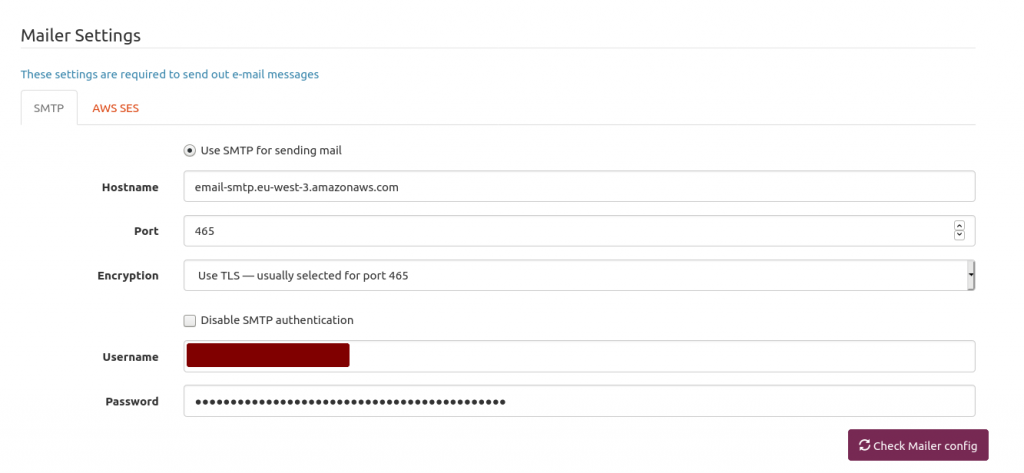 Mailtrain mailer setup
Mailtrain mailer setup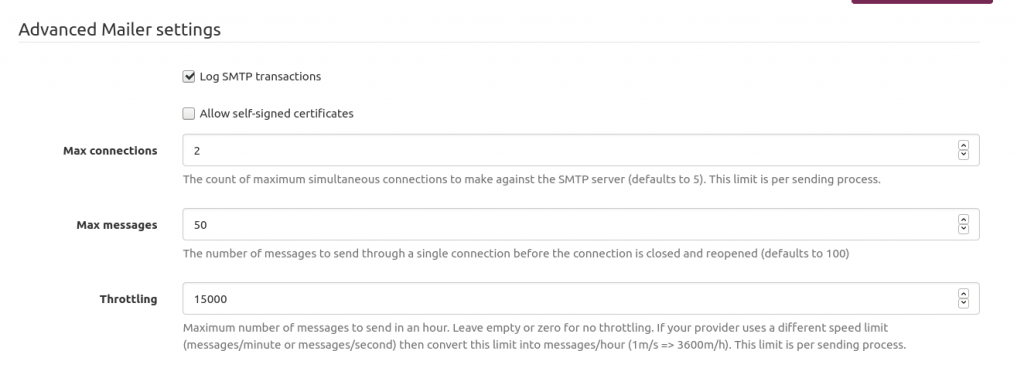 Mailtrain to throttle sending emails to AWS SES
Mailtrain to throttle sending emails to AWS SES

 The red commemorative plaque not only limits Orwell's tenure to the time he was permanently in the village, it omits all reference to his first wife, Eileen O'Shaughnessy, whom he married in the village church in 1936.
The red commemorative plaque not only limits Orwell's tenure to the time he was permanently in the village, it omits all reference to his first wife, Eileen O'Shaughnessy, whom he married in the village church in 1936. Wallington's Manor Farm, the inspiration for the farm in Animal Farm. The lower sign enjoins the public to inform the police "if you see anyone on the [church] roof acting suspiciously". Non-UK-residents may be surprised to learn about the systematic theft of lead.
Wallington's Manor Farm, the inspiration for the farm in Animal Farm. The lower sign enjoins the public to inform the police "if you see anyone on the [church] roof acting suspiciously". Non-UK-residents may be surprised to learn about the systematic theft of lead. It all started with the big bang! We nearly lost 33 of 36 disks on a
It all started with the big bang! We nearly lost 33 of 36 disks on a 
 In 14 years since starting this blog, I changed the software several times,
with each iteration simplifying requirements and setup.
Wordpress
In 2007, I
In 14 years since starting this blog, I changed the software several times,
with each iteration simplifying requirements and setup.
Wordpress
In 2007, I